(304100) 솔트룩스 - (3) 그래프 DB ( Graph DB Suite 기술소개 )
saltlux

- 동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
- 동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
- 아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
그래프 DB (Graph DB Suite)

그래프 데이터베이스 인식 및 기술 패러다임 변화
2018년 기준으로 전세계 GraphDB 시장 중 아시아의 비중은 18.2%로 미국이나 유럽보다 시장 규모는 작지만, 년 상승률은 28.3%로 가장 큰 것으로 나타나고 있습니다. 따라서 아시아 IT 인프라 발전과 중·소 규모의 GraphDB 기업들의 가치가 다른 대륙 기업들의 기대치보다 높게 나타나고 있습니다.

< 그래프 데이터베이스의 시장 점유율 및 상승율(2018년) >
시장 변화에 따른 제품 혁신의 통찰력
현재 GraphDB 시장은 기업들의 시장 욕구를 토대로 기술력이 발전하면서 점차적으로 확대되어 2023년에는 전세계적으로 2.4 billions 규모로 커질 것으로 기대하고 있습니다. 이에 따라 솔트룩스는 내제된 솔루션을 정립하고 더 나아가 맞춤형 솔루션을 체계화하여 시장 대응력을 강화하였습니다.

< 그래프 데이터베이스 마켓 성장 및 기술변환에 따른 시장 성장 >
소개
GraphDB Suite는 다양하고 방대하게 쏟아지고 있는 빅데이터를 효율적으로 활용 및 관리하기 위하여 데이터 간의 상관관계를 지식그래프 구조로 자동 변환·생성하여 저장뿐만 아니라 분석에 바로 활용할 수 있는 분석 기능을 내장합니다. 또한, 국내 최고의 지식그래프데이터 생성에서부터 관리, 지능형 분석(예측·추론)이 가능한 최고의 제품으로 비즈니스 환경에 따라 Add-on 패키지를 선택적으로 사용하여 데이터 통합, 리스크 관리, 콘텐츠 추천, 데이터 공개, 대용량 추론 기능을 제공합니다.

< GraphDB Suite 개념도 >
GraphDB Suite은 멀티 데이터 모델 통합 서비스, 데이터 예측/진단 서비스, 링크드 오픈 데이터 서비스, 대용량 지식그래프 구축 서비스를 구축할 수 있는 환경을 제공하고 있습니다.

< GraphDB Suite 구성도 >
주요 기능
GraphDB Suite는 데이터를 그래프데이터로 변환하기 위한 변환기능, 그래프데이터 저장소, 그래프데이터 기반 지오데이터 분석과 지식 네트워크 분석, 그래프데이터 개방 기능, 시각화와 운영관리에 이르는 그래프데이터의 생명주기에 해당하는 모든 기능을 제공하고 있습니다.
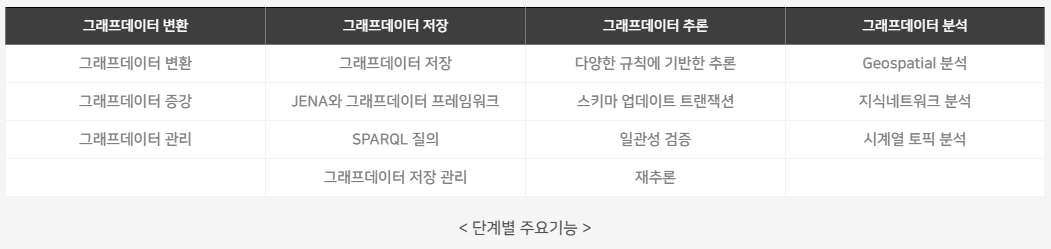
주요 특성
GraphDB Suite은 비즈니스 환경에 따라 최적화된 솔루션을 선택하여 적용해야 합니다. 비즈니스 환경은 기업이나 기관이 보유한 데이터의 유입 속도, 데이터의 볼륨에 따라 크게 좌우되며, 또한 서비스의 종류에 따라 지식베이스 구축의 기술 난이도도 상이하게 달라지게 됩니다. GraphDB Suite는 고객의 니즈를 충족시키고 최적화된 서비스를 제공할 수 있게 함으로써 그래프 데이터 기반의 새로운 시장창출과 고객발굴, 고객의 경제적 가치를 높이는 최적의 솔루션입니다.

주요 경쟁력
GraphDB Suite 제품은 지식그래프 기반 인공지능기반 서비스(고객상담 서비스, 인공지능 스피커의 질의응답 서비스 등)와 결합된 국내 최초 제품입니다. GraphDB Suite은 그래프 데이터변환부터 통합, 저장, 추론/질의, 분석, 관리, 활용에 필요한 모든 기능을 하나의 프레임워크에서 제공하는 플랫폼입니다.

그래프데이터변환 엔진
구조화 데이터에는 RDBMS, 엑셀, CSV, TSV, RDF 등 데이터가 일정한 구조를 가지는 것을 말하며, 비구조화 데이터는 웹문서, 매뉴얼 등의 문서의 구조를 가지는 데이터를 말하며, 이렇게 내/외부 산재되어 있는 다양한 대용량의 데이터들 간의 아주 복잡한 관계를 더 쉽고 빠르게 파악할 수 있도록 Graph DB에 저장하기 위하여 그래프데이터로 변환하여 통합 처리하는 프로세스에서 시작합니다.
데이터를 변환하는 방법에는 데이터 소스의 구조와 지식그래프 데이터 모델을 매핑하거나 비구조화된 문서에서 지식그래프 모델에 해당되는 특정 리소스의 속성, 값 형태로 데이터를 추출하여 그래프 데이터로 변환할 수 있습니다. 또한, W3C의 RDF Direct Mapping 기술을 통해서 RDB와 RDF를 직접 연결하고 통합할 수 있습니다.
솔트룩스의 데이터변환엔진은 변환 및 통합을 위한 매핑 언어인 RML(Rule Mapping Language)과 W3C의 R2RML을 지원하고 있으며, RDB 뿐만 아니라 다양한 데이터 소스를 지원하고 매핑 과정에서 데이터에 대한 정제 및 필터링을 지원함으로써 양질의 그래프데이터 확보 및 처리에 적합한 엔진입니다.

< 그래프데이터변환 엔진 – 데이터변환 개념도 >
소개
그래프데이터변환 엔진은 데이터 소스(DBMS, CSV, RDF 등)와 지식그래프 모델간 매핑을 통해 지식그래프에 해당되는 데이터를 생성하기 위한 엔진입니다. W3C의 R2RML언어 지원뿐만 아니라 자체 데이터변환 규칙인 RML언어 제공을 통해 RDB와 같은 구조화된 형태를 가지는 모든 데이터를 대상으로 변환하는 기능을 제공하며, 사용자 데이터를 가상의 데이터 뷰(Data View)로 전환하고 처리하기 위한 기능을 제공하고 있습니다. 사용자는 그래프데이터변환엔진을 통해 데이터변환 업무를 쉽고 빠르게 수행할 수 있습니다.
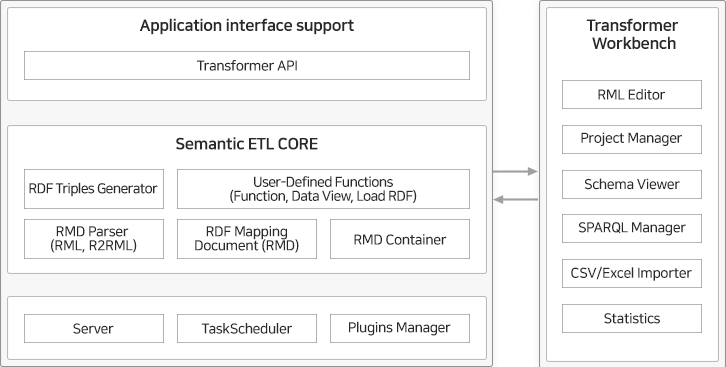
< 그래프데이터변환 엔진 – 기능 구성도 >
데이터변환 엔진의 관리 기능은 데이터 매핑 및 변환 뿐만 아니라 데이터 소스 뷰어, 데이터 모델(스키마) 뷰어, SPARQL 뷰어 및 테스트, CSV/Excel 파일 뷰어, RML 편집기 및 테스트, 변환 통계기능 등 사용자가 데이터변환 처리(데이터 전처리, 변환, 데이터 후처리)에 있어 유용한 기능을 제공하고 있습니다.

< 그래프데이터 변환 절차 >
데이터변환 절차는 데이터 소스 선정, 데이터 소스에 해당되는 데이터 뷰 생성, 그래프 맵 정의, 데이터 뷰와 그래프 맵 바인딩, 그래프데이터 생성의 절차로 진행합니다. 그래프 맵은 그래프 모델에 해당되는 인스턴스를 정의하며 특정 리소스의 속성값을 생성할 때 값에 대한 필터링/정제가 필요할 경우는 함수를 이용하여 처리합니다.

< 대용량 비졍형데이터 지식 추출 절차 및 도구 >
주요 특징
그래프데이터변환 엔진은 대용량 데이터에 대한 변환뿐만 아니라 다양한 데이터 소스를 지원하는 가상의 데이터 뷰를 제공, 데이터변환 시 데이터에 대한 정제 및 필터링 제공 등 사용자가 정의한 데이터 뷰와 필터링 함수를 직접 정의하고 엔진에 적용할 수 있습니다. 그래프데이터변환 엔진의 가장 큰 장점은 사용자가 데이터 뷰(Data View)를 만들거나 사용자 함수(필터링, 정제 등)을 플러그인으로 만들 수 있으며, 이들은 모두 URI주소를 가지고 있어 다른 프로젝트(작업)에서 동일한 함수가 URI를 통해서 구분하여 사용할 수 있는 장점이 있습니다. 또한, 형상관리 서버(SVN, CVS, Git 등)와의 연동을 통해 작업중인 프로젝트 별 형상을 관리할 수 있습니다. 다음과 같은 주요 특징들을 가지고 있습니다.

주요 기능 및 사양
Graph DB Suite에 정형과 비정형 데이터에 대한 그래프데이터 생성을 담당하는 그래프데이터변환 엔진은 데이터변환 핵심기능과 손쉬운 변환 작업을 지원하는 관리도구로 구성되어 있습니다. 정형화된 데이터의 경우 스키마 매핑을 통해 데이터를 추출/변환할 수 있으며, 비정형화 데이터의 경우는 KENT의 데이터 추출 기능을 결합하여 데이터 모델에 필요한 속성의 값을 추출하고 변환할 수 있습니다.
다양한 포맷을 지원하는 데이터변환 기능
Graph DB Suite의 데이터변환 기능은 그래프데이터를 생성하기 위한 절차와 방법을 제공하고 있으며, 변환 전 결과에 대한 사전 테스트와 변환 결과를 Graph DB에 직접 저장할 수 있는 기능을 제공하고 있습니다. 핵심 기능들은 대부분 플러그인 형태로 구성되어 사용자 환경에 맞게 기능을 최적화할 수 있는 있습니다.

초 대용량 그래프 데이터변환과 증강 기능
그래프데이터변환 엔진은 위키피디아, 위키데이터 등 내/외부에 존재하는 큰 데이터셋에 대한 지식변환과 지식그래프 데이터에 대한 증강 및 오류보정 등 복잡한 데이터변환 프로세스와 방법을 제공합니다.
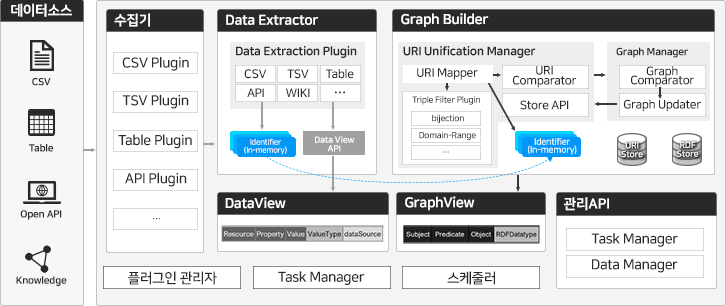
데이터 수집, 추출, 리소스 통합 및 보정, 그래프 데이터 생성 등의 기능을 제공하고 있으며, 플러그인 방식으로 기능을 추가하거나 최적화할 수 있습니다. 또한, 변환과정을 관리하고 통제하기 위한 관리 API를 제공하고 있습니다.
데이터변환 엔진 관리 기능
변환 엔진 관리도구에는 데이터변환 규칙 편집 및 실행, 데이터 소스, 사용자 함수, SPARQL, 리소스 뷰어 등의 기능이 있으며 사용자는 해당 기능을 사용하여 변환 규칙을 쉽고 빠르게 작성할 수 있습니다. 변환 엔진의 모든 함수는 네임스페이스에 기반하고 있어 중복되는 함수이름도 네임스페이스를 통해 구분하고 사용할 수 있습니다. 관리도구의 규칙 편집기는 변수, 함수 등에 대한 자동완성을 제공하고 있으며, 사용자의 데이터 모델을 가져오기 하면 자동으로 클래스, 속성을 편집기에서 자동완성 항목에 포함시켜 사용자가 클래스/속성을 쉽게 참조하여 변환규칙을 생성하는 데 사용할 수 있습니다.

주요 엔진 화면

그래프데이터저장 엔진
Graph DB Suite에서 100억 트리플 이상의 초 대용량 그래프데이터를 저장하고 활용할 수 있는 그래프데이터 저장 엔진을 제공하고 있습니다. 그래프데이터 저장 엔진은 개념간 상·하위 추론과 관계추론 및 검증을 위한 3.3.2.3의 공리(Axiom)를 제공하고 있으며, 이를 통해 새로운 사실을 생성하고 저장할 수 있습니다.
Graph DB Suite은 W3C의 그래프 모델인 RDFS, OWL과 OWL2을 지원하고 있으며, 아파치 TinkerPop과 Gremlin 서버 연동을 통해 (Labeled) Property Graph 모델을 저장하고 질의할 수 있습니다. 사용자는 2가지의 데이터모델을 목적에 따라 선택적으로 사용이 가능합니다.
그래프데이터 저장 엔진은 데이터를 조회, 수정/삭제하기 위한 질의 언어를 제공합니다. W3C의 SPARQL과 GraphQL를 제공하고 있으며, 데이터 개방, 공유, 분석 등을 위해서 Rest기반 API를 통해 쉽고 빠르게 접근할 수 있습니다.
소개
그래프데이터 저장 엔진은 기본적으로 RDF기반 그래프데이터를 저장하는 저장소와 Property Graph를 저장하는 저장소 기능을 제공하며, 아파치 TinkerPop과 Gremlin 서버 연계를 통해 Property Graph를 저장하고 분석할 수 있는 기능을 제공하고 있습니다. RDF기반 그래프데이터는 트리플(triple)로 데이터가 표현되고, Property Graph는 Vertex, Edge로 표현되고 Vertex와 Edge은 속성(property)를 가질 수 있습니다.
주요 특징

주요 기능 및 사양



주요 엔진 화면

그래프데이터추론 엔진
Graph DB Suite에서 강력한 지식표현과 추론, 그래프 데이터의 저장은 추론을 통해 변환된 데이터로부터 새로운 사실을 발견하고 저장할 수 있습니다. 특히 데이터 모델에서 개념 간의 상·하위 추론과 개념 간의 관계추론을 위한 스키마 공리와 인스턴스 공리를 제공하고 있습니다.
Graph DB Suite은 W3C의 그래프 모델인 RDFS, OWL1, OWL2을 지원하고 있으며, (Labeled) Property Graph 모델을 저장하고 질의할 수 있습니다. 사용자는 2가지의 데이터모델을 목적에 따라 선택적으로 사용이 가능합니다.
소개
그래프데이터추론 엔진은 규칙기반 추론을 위한 2가지 리즈닝 전략(전방연쇄 (forward-chaining)과 후방연쇄(backward-chaining))을 제공하고 있습니다. 기본적으로 전방연쇄에 기반한 추론전략을 제공하며 필요시 후방연쇄 추론엔진을 사용할 수 있습니다. 전방연쇄에 기반한 추론의 장단점은 데이터가 저장소에 트랜잭션 후에 유추된 사실을 확장하기 때문에 새로운 사실을 업로드, 저장, 추가, 삭제 시 상대적으로 느려질 수 있습니다. 그래프데이터추론 엔진에서 추론은 데이터 입력 시점부터 시작됩니다. 하지만, 전방연쇄 추론기법의 장점은 모든 데이터에 대한 추론결과를 미리 만들어 저장함으로써 질의와 검색에 상당히 빠른 성능을 제공합니다. 일반적으로 후방연쇄 추론기법은 질의나 검색 시 추론이 발생하며 이로 인해 복잡한 연역추론이나 적합성 검사나 다른 추론이 발생할 가능성이 높아 성능에 영향을 미칠 수 있습니다.
주요 특징
그래프데이터 저장과 분석은 강력한 지식표현과 데이터 멀티 모델 지원을 통한 데이터 통합, 그래프데이터에 대한 다양한 분석기능을 제공합니다. 그래프데이터 저장과 분석의 주요 특징은 다음과 같습니다.

주요 기능 및 사양




주요 엔진 화면

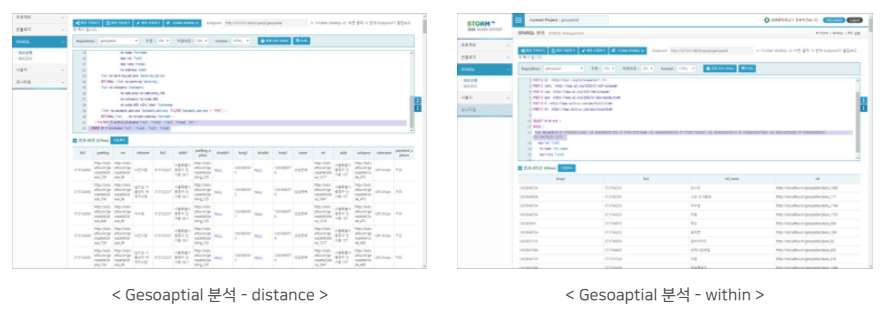
그래프데이터분석 엔진
Graph DB Suite의 그래프데이터분석 엔진은 그래프데이터 기반 공간정보분석, 네트워크분석, 토픽분석을 제공합니다.
소개
그래프데이터분석 엔진은 외부정보(소셜미디어, 이메일, 지식관리 시스템 등)에 대한 지식그래프 생성기, 지식네트워크 분석을 위한 그래프 인덱스 생성기, 사용자별, 시간대별, 토픽별 지식네트워크 분석기, 네트워크 상에 유통되는 컨텐츠에 토픽(핵심어)분석을 위한 토픽네트워크 분석기, 시간대별 관심 토픽에 대한 경향성 분석기, 지식 검색기로 구성되어 있습니다.
주요 특징
그래프데이터분석 엔진의 특징은 실시간으로 수집/변경되는 지식에 대한 실시간 반영과 분석을 제공하며, 특히 수집된 데이터를 지식으로 변환하는 그래프데이터변환 엔진을 포함하고 있습니다. 또한, 그래프데이터분석에 필요한 데이터의 저장과 분석 색인 및 알고리즘을 제공하고 있으며, 분석 서비스 관점에 따라 사용자가 적절한 분석 알고리즘을 선택하여 결과를 얻을 수 있습니다. 모든 결과는 테이블 형태뿐만 아니라 RDF포멧(RDF/XML, Turtle, N-Triple, RDF/JSON 등)을 지원하고 있습니다.
주요 기능 및 사양



주요 엔진 화면

그래프 DB (Graph DB Suite) 적용사례

컴플라이언스 시스템 구축
지능형 범죄예방 협업 체계 개발 – 대검찰청
“국민안전”이 정부의 주요 국정전략임에도 불구하고 일시적인 인력·예산 투자 (치안인력 증원, CCTV 설치, 캠페인 강화 등) 및 기관별 범죄예방활동만으로는 지속적이고 장기적인 범죄예방 어려움을 겪고 있습니다. 발생 범죄를 세부적으로 분석하고 관계기관간 정보를 공유, 협업하여 국민에게 실효성 있는 범죄예방을 위한 과학적인 범죄분석체계 확립을 통하여 선제적 예방 중심의 형사사법체계 강화할 수 있는 지능적 시스템이 필요하며, 범죄정보, 행정사회정보를 과학적으로 분석하고, 관계기관이 공유하여 교육, 수사, 범죄자 사후 관리 및 피해자·가해자의 정상적인 사회 복귀 실현을 위한 국민정부지방간 긴밀한 공동의 협업 시스템 필요한 상황입니다. 이러한 두가지 관점의 큰 문제점을 해결하기 위하여 과학적인 범죄분석 기반 시스템 구축과 범죄 그래프데이터 기반의 지능형 범죄분석체계 확립 및 관계기관간 범죄예방 협업체계 구성 기반을 마련하였습니다.

< 지능형 범죄예방 분석시스템 >
① 사업의 내용
- 과학적인 범죄분석 기반 시스템 구축
- 5대 강력범죄 (살인, 성폭행, 강도, 방화, 폭행상해치사)에 대한 정형/비정형 데이터 융합 분석 인프라 구축
- 약 800여종의 반정형 비정형 문서 텍스트 분석
- 범죄분석을 지원하는 다양한 시나리오 설계
- 범인의 음성, 영상, 사진 등 범죄 증거자료 분석
- 기술 방법론 연구 (외부 POC 수행)
- 지능형 범죄분석 지식 기반 구축
- 심층 범죄 분석을 위한 기반 자료 구축
- 심층 범죄 분석용 컨셉사전 및 범죄 분류체계 구축
- 심층 범죄 분석의 자동화를 위한 기계학습 데이터 및 지식표현 체계 구축
- 관계기관간 범죄예방 협업체계 기반마련
- 관계기관 범죄예방 수립 시 요구되는 정보 식별
- 관계기관 연계 기반 방안 마련
② 적용 기술 및 솔루션
- Graph DB Suite 제품 적용
범죄 분석에 필요한 Concept사전, Taxonomy, 범죄유형정보, 분석모델을 기반으로 범죄사전 정보에 대한 그래프데이터 생성 및 저장, 추론, 분석을 위하여 Graph DB Suite 제품 적용 - Big Data Suite 제품 적용
Big Data Suite 제품 중 지능형 시맨틱 검색 서비스를 위하여 빅데이터 저장/검색엔진(DISCOVERY)과 수집된 비정형 데이터 분석을 위하여 비정형 빅데이터 분석 엔진(TMS), 인지 분석 엔진(CAS)를 적용 - Apach SPARK, STORM, KAFKA 등 적용
OpenSource Apach SPARK, STORM, KAFKA 등을 지능형 범죄예방 분석시스템에 반영하여 Graph DB Suite 제품, Big Data Suite 제품과 연계를 통한 최적의 품질을 보장하는 지능형 분석 플랫폼 구성
③ 제품 선정 당위성
- 온톨로지 기반 실시간 분석 및 객체간 관계 시각화 필요
- 과학수사, 형사정책, 범죄예방 관련 분석 결과에 대한 시각화 필요
- 한국 범죄에 특화된 범죄 텍사노미 구성 필요
그래프데이터 통합 플랫폼 구축
지능형 KMS 시스템 구축 – 농협은행
농협은행 고객행복센터 및 전 영업점에서 고객상담에 필요한 업무 지식을 관리하고 공유하는 지식관리 시스템을 개선하였습니다. 지식 생성, 관리, 검색 등의 사용 편의성을 높이고, 지식 컨텐츠 생성 시, 업무 분야와 속성에 따라 구체적으로 관리되도록 하여 Knowledge-Graph 기반의 지식베이스로 변환 저장합니다. 이는 자연어 컨텐츠를 시스템이 이해 가능한 형태(machine readable)의 지식 데이터로 변환하는 것이며, 이 과정에서 인공지능 기반 지식 자동 추출도 적용하였습니다.
< 지능형 KMS 시스템 UI/UX >
① 사업의 내용
기존의 지식관리 시스템은 고객 상담을 위해 필요한 업무 지식을 생산, 저장 관리하는 시스템으로, 은행 상담사 또는 영업점 직원들 간 지식을 공유하기 위한 목적으로 사용되고 있습니다. 하지만, 은행 고객들의 다양한 디지털 채널 사용이 많아 짐에 따라, 인공지능 기반의 서비스 요구가 지속적 증가하고 있고, 인공지능 서비스를 위해서는 별도의 AI 기반 지식 데이터구축 관리가 필요합니다. 기존 지식 컨텐츠와 AI 기반 지식 데이터는 형태와 구조가 서로 상이하여 개별적으로 관리하기에는 동일한 정보를 유지하기 어렵고, 중복된 지식 생성, 관리 및 활용으로 여러 측면에서 사용자에게 불편함을 주고 있는 상태입니다. 농협 은행에서는 10년 이상 사용한 노후화된 지식관리 시스템을 최신 인공지능 기술 트렌드에 부합하는 지능형 지식관리 시스템으로 개편하여, 직원들 간 상담 지식정보 관리 및 공유의 편의성을 높이는 것은 물론, 인공지능 기반 서비스에 활용 가능한 지식 데이터를 동시에 생성 관리함으로써, 지식 컨텐츠의 관리 효율성과 활용성을 높이는 것을 목표로 합니다.

< 지능형 KMS 시스템 개요 >
② 적용 기술 및 솔루션
- 지식그래프 기반의 지식 데이터 생성 관리
지능형 지식관리 시스템에서는 지식 컨텐츠를 생성할 뿐만 아니라, 지식그래프(Knowledge-graph) 구조에 따라 시스템이 이해 가능한 형태(machine readable)의 지식 데이터를 생성하고 관리할 수 있습니다. 이러한 지식 베이스는 다양한 인공지능 기반 서비스에 활용될 수 있습니다. - 비정형 텍스트로부터 지식 자동 추출
지식 컨텐츠는 사용자들이 쉽게 이해 가능한 형태(TEXT 또는 HTML)의 문장 또는 단락으로 작성되어 있습니다. KENT(Knowledge Extraction from Natural Language Text) 기술은 딥러닝으로 학습된 모델을 기반으로 이러한 비정형 텍스트로부터 지식 데이터를 자동으로 추출하고 변환합니다.
③ 제품 선정 당위성
- 국내 최고의 품질 및 성능을 보유한 지식그래프를 저장하기 위한 저장소 선정
- 비정형 문서의 지식 추출을 위한 기계학습기반의 지식 추출 솔루션 선정
④ 주요 성과
- 농협은행/농협카드 지능형 지식관리 시스템과 질의응답 시스템 연계
농협은행과 농협카드의 지능형 지식관리 시스템을 각각 구축하여 별도의 컨텐츠를 관리하고 서로 지식 공유가 가능하도록 연계하였습니다. 또한, 콜센터 상담 어드바이저로 서비스되는 인공지능 질의응답 시스템과 연계하여 지능형 지식관리 시스템을 통해 관리는 지식데이터가 직원들과 시스템에 동시에 서비스되는 환경을 구축하였습니다. - 지식 자동 추출 기술 상용화
지식 자동 추출은 아직까지 많은 연구 개발의 노력이 필요한 기술 분야입니다. 품질 향상을 위해 언어처리와 기계학습을 포함한 다양한 방안들을 연구하였고, 농협은행의 컨텐츠로부터 필요한 지식을 추출하는 범위에서는 만족할 만한 수준의 성과를 보였습니다. 지식 자동 추출을 실제 서비스에 적용한 성공 사례로 볼 수 있습니다.
안전 먹거리 질의응답 시스템 - 한국식품안전관리인증원
① 사업의 내용
- 국민생활과 밀접한 HACCP 인증 안심먹거리 기반으로 제품의 원재료, 영양성분 데이터를 활용하여 지식베이스를 구축하고, 더 나아가 테마기반의 개인화된 안심먹거리 추천 서비스를 대국민에게 제공할 수 있는 “HACCP 지능정보서비스를 위한 인공지능 기반 고객 맞춤형 지식 상담 서비스 개발”을 목표로 합니다.

< 안전먹거리 질의응답 시스템 목표 구성도 >

< 안전먹거리 질의응답 UI/UX >
② 적용 기술 및 솔루션
- QA Manager: 사용자 질의처리와 인터페이스 제공(Open API)
- KBQA: FBQA & TBQA &Plugin
- FBQA: 팩트(facts)기반 질의처리
- TBQA: 템플릿 기반 질의처리 기능, 복잡하거나 복합적인 질의처리
- Plugin: 날씨, 뉴스, 세계시간 등 실시간 변경되는 데이터에 대한 질의처리
- IRQA: 텍스트 분석을 통해 질문과 유사한 질문을 찾아 랭킹 된 답변을 제공
- KB(Ontology): 질의처리에 필요한 오픈 도메인 지식베이스(OWL ontology: RDF + Axioms)
- NLU: 자연어 질의 분석 및 패턴인식
- NLG: 질의처리 결과에 대한 자연어 질의 생성
- 분석사전관리: 질의분석 및 질의패턴에 필요한 자원관리
- QA관리: KB관리, 질의테스트, QA평가, KBQA분석사전관리
③ 제품 선정 당위성
- 지식그래프를 저장하기 위한 저장소 사용
- 비정형 문서의 지식 추출을 위한 기계학습 솔루션 사용
④ 주요 성과
- 사용자들에게 테마기반의 맞춤형 식품정보를 제공 가능
- 정보취약계층에 대한 접근성을 강화하고 안심먹거리에 대한 알 권리 향상
- 지능형 안심먹거리 서비스의 정보 획득 시간 단축 비용절감 효과
- 지능형 HACCP 상담서비스의 민원상담 및 기술지원방면의 비용절감 효과 기대
링크드 데이터(LOD) 서비스 구축
맞춤형 IP-Biz 정보공유 플랫폼 개발 – 특허청
① 사업의 내용
특허청이 보유한 지식재산권 정보를 중심으로 타 정부부처 및 공공기관이 보유 중인 다양한 비즈니스 정보를 연계하여 활용할 수 있는 정보채널을 구축하고, 중소기업 및 창업기업 등 기업 종사자들이 빠르고 편리하게 정보를 획득할 수 있는 사용자 관점의 편의 기능을 제공하였습니다.
- 타 정부부처 및 공공기관 보유 비즈니스 정보 연계
- 특허청 보유 지식재산권 정보와 비즈니스 정보 융합 및 맞춤형 제공
- 구축된 지식재산권 정보와 비즈니스 정보를 바탕으로 사용자 맞춤 보고서 제공

< 맞춤형 IP-Biz 정보공유 플랫폼 구성도 >
② 적용 기술 및 솔루션
- 텍스트 마이닝 키워드(주제어) 추출
- 트렌드 분석 및 TopN 분석
- 연관관계 분석을 위한 지식그래프 적용
③ 제품 선정 당위성
- 지식그래프를 저장하기 위한 저장소 사용
- 비정형 문서의 지식 추출을 위한 기계학습 솔루션 사용
- 동향 및 트렌드 분석을 위한 텍스트마이닝 및 시계열 분석 기술 솔루션

< 특허동향/기술/시장 분석 서비스 UI/UX >
③ 주요 성과
- 국내외 500만건 이상의 특허정보 공개
- 13개 기관 300만 건의 특허 분석 DB 연계 정보 제공
- 제품 유형별 분석서비스 제공
- 기업 맞춤형 분석 리포트 제공
그래프 DB (Graph DB Suite) 기술소개



'*기업 & 종목 소개 > - KOSDAQ 코스닥' 카테고리의 다른 글
| (304100) 솔트룩스 - (5) 솔루션 Solution (0) | 2021.01.01 |
|---|---|
| (304100) 솔트룩스 - (4) 클라우드 서비스 Cloud Service (0) | 2021.01.01 |
| (304100) 솔트룩스 - (2) 빅데이터 ( Bigdata Suite 기술소개 ) (0) | 2021.01.01 |
| (304100) 솔트룩스 - (1) 회사소개 & 인공지능 ( AI Suite , 적용사례 , 기술소개 ) (0) | 2021.01.01 |
| (314130) 지놈앤컴퍼니 - (1) 회사소개 & 원천기술 (0) | 2020.12.30 |