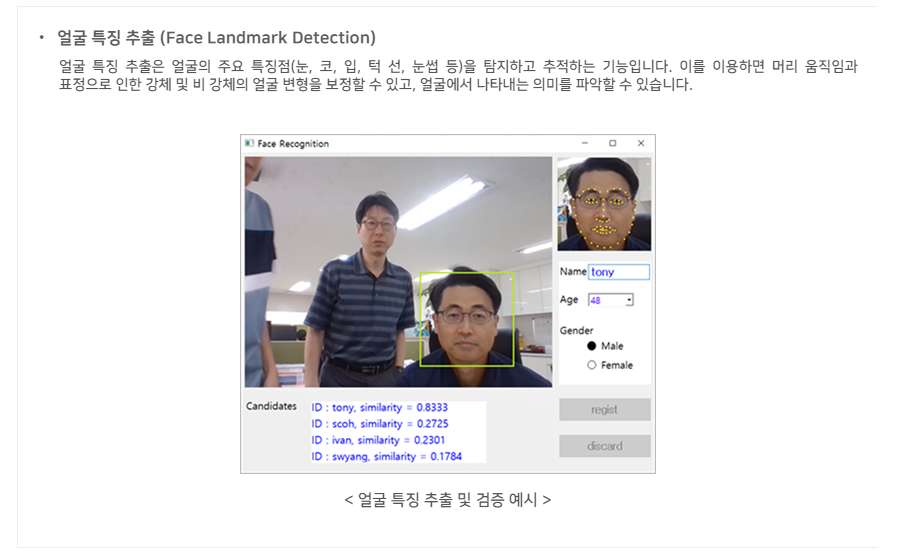
동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
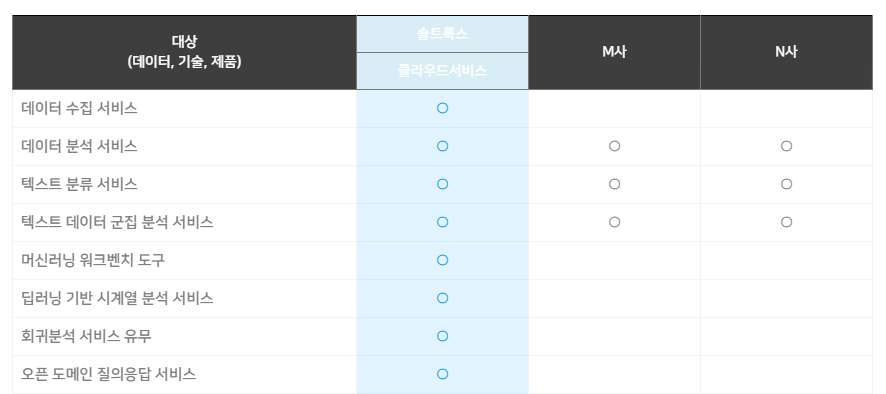
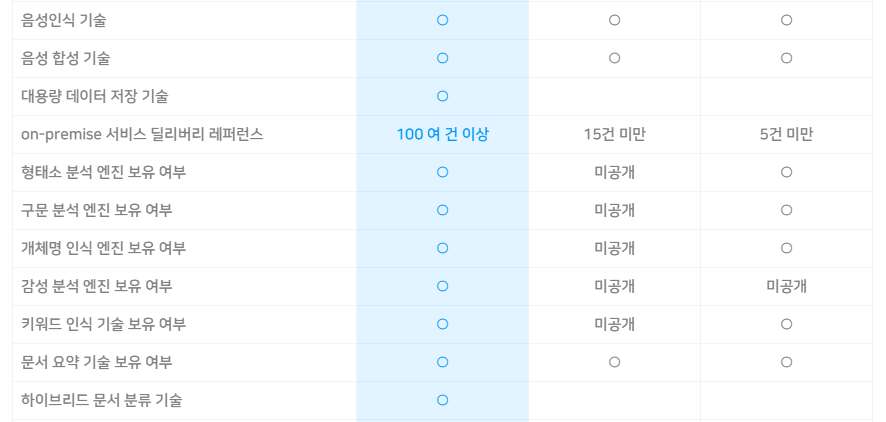
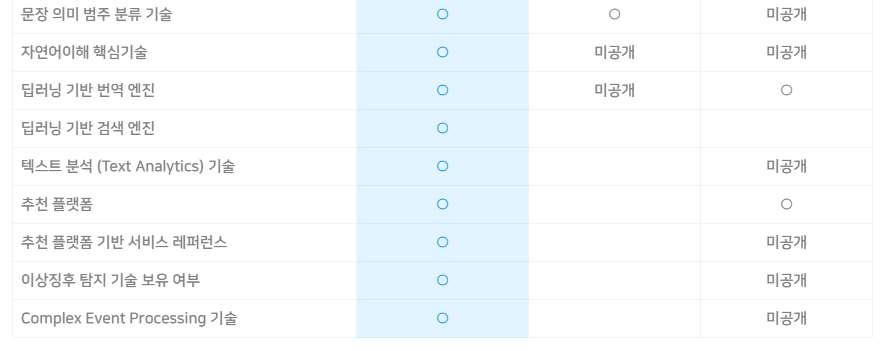
솔루션 Solution
고객 목소리 분석 VOC
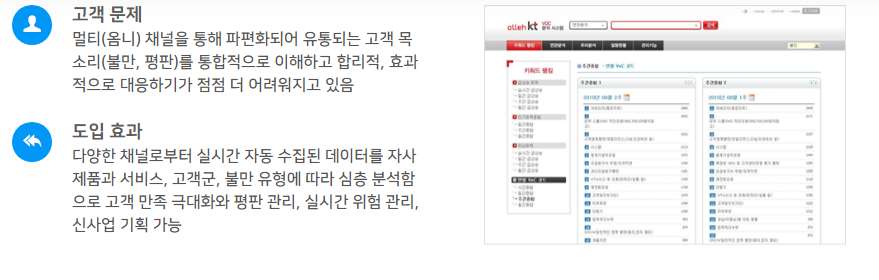
최근 금융감독원의 민원접수에 따른 은행평가, 금융소비자보호규범 준수, 빅데이터와 결합한 VOC 분석, 상담 녹취 데이터 활용 등에 대한 고객의 관심과 요구가 증가하고 있습니다. 단편적인 고객 불만에 신속하게 대응하는 프로세스를 벗어나 기업은 고객의 전반적인 경험을 주도적으로 찾아내어 전사적으로 고객의 잠재적 요구에 신속하게 대응하는 Sense & Response 경영체제로 진화를 준비합니다. 또한, 인터넷, 모바일, 소셜미디어 등의 일상화로 자사 제품/서비스에 대한 고객의 의견과 불만을 통합적으로 이해하고 효과적으로 대응하기가 점점 더 어려워지고 있습니다. 특히, 회사로 유입되지 않고 인터넷과 소셜미디어를 통해 유통되는 자사 제품/서비스에 대한 평판과 불만은 예측하기 어려운 미래 위험이 되기도 합니다.
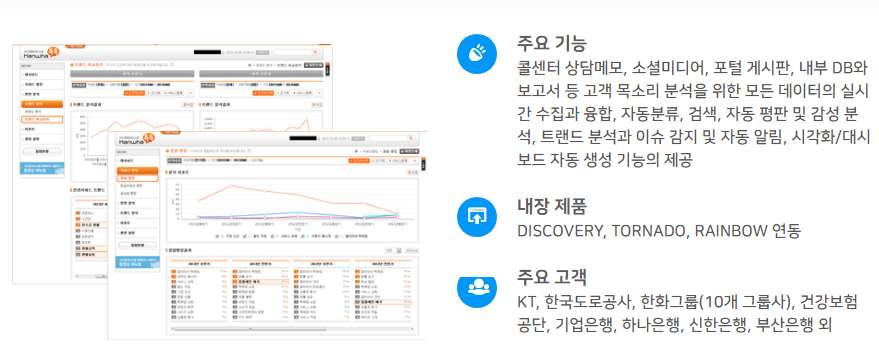
솔트룩스의 고객 목소리(VOC) 분석 솔루션은 고객센터의 상담 메모뿐 아니라 이메일, 다양한 소셜 미디어와 포털 게시판에 이르기까지 다양한 채널로부터 고객 목소리를 실시간 수집, 통합합니다. 고객 불만과 평판을 심층 분석하고 이상징후 조기 감지 및 실시간 대응 체계를 제공함으로 고객 만족 극대화, VVIP 대응, 회사와 서비스 평판 관리뿐 아니라 신상품 개발에 이르기까지 보다 지능적이고 주도적인 대고객 리더십 확보를 지원합니다.
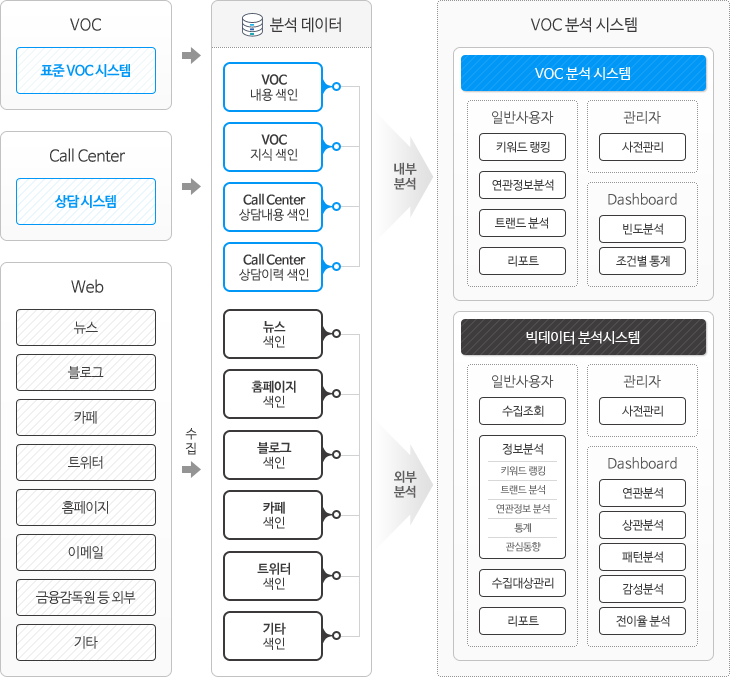
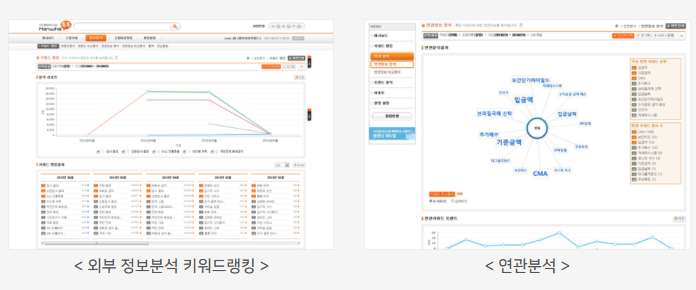
< 통합 VOC 분석 웹 서비스 >
VOC시스템의 정의
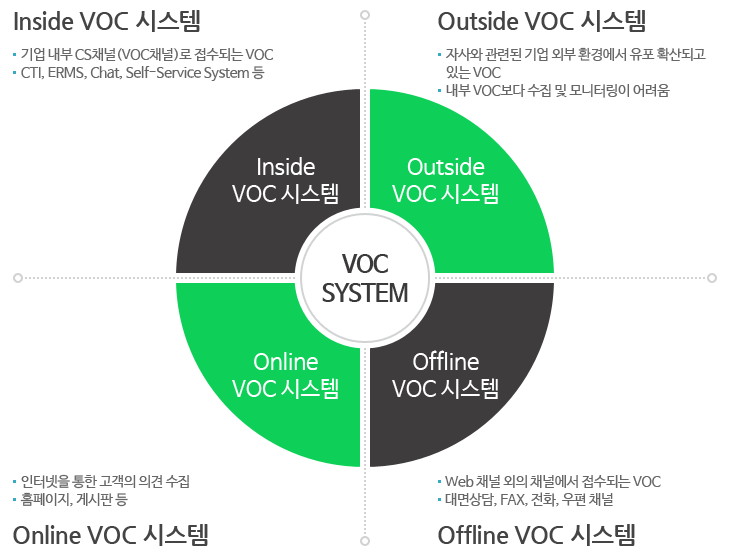
VOC(Voice Of Customer) 는 기업의 경영 활동에 있어서 고객들이 기업의 서비스에 반응하는 각종 문의, 불만, 제안 등을 의미합니다. 이러한 VOC을 구성하고 있는 데이터는 주로 콜센터 등에서 사용하는 CRM의 고객지원 시스템을 통해 확보할 수 있는 상담원의 고객상담메모, 고객지원 게시판이며, 최근에는 블로그, 트위터, 커뮤니티 사이트의 다양한 채널을 통해 확보가 가능한 고객제품, 서비스의 반응 등 데이터를 포괄적으로 포함합니다.
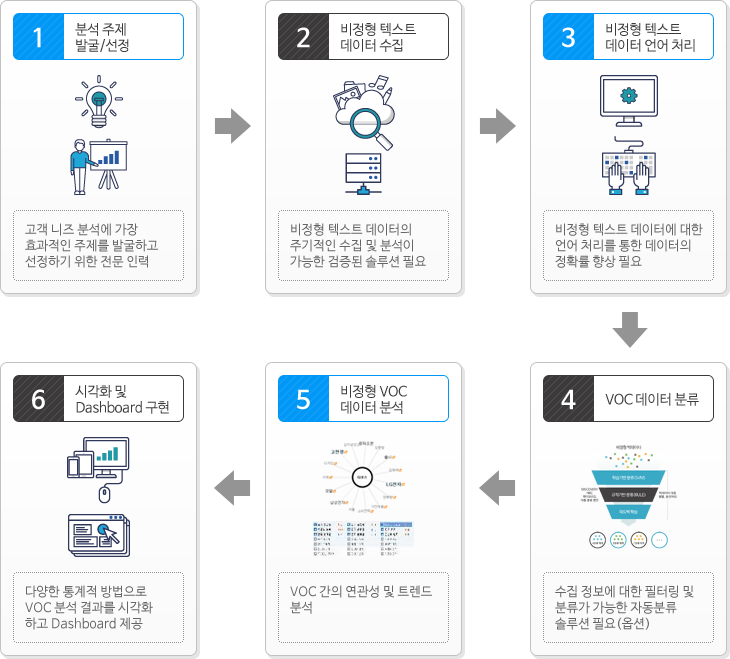
솔트룩스 VOC 분석 솔루션은 내/외부 비정형 VOC(상담) 정보를 수집하는 정보 수집 시스템과 수집된 정보를 분석하는 VOC 분석 시스템 그리고 분석된 정보를 웹으로 제공하는 웹 서비스로 구성됩니다. 비정형 Data(VOC, 상담기록) 분석을 위해 다양한 구축 사례를 통하여 성능이 검증되고 기능이 최적화된 텍스트마이닝, 연관정보검색 등 데이터 수집/분석 솔루션을 활용하여 성공적인 상담 기록 분석 시스템을 구축합니다.
< VOC 단계별 프로세스 >
VOC분석의 필요성
2000년 대 CRM 시스템을 포함하는 대규모 콜센터 인프라의 구축으로 인하여 대용량의 고객 상담 메모가 시스템 상에 지속적으로 축적되어 왔습니다. 또한 디지털 환경의 보편화 및 인터넷 환경 등이 활성화 되며 소비자의 적극적인 의사 표현이 이루어 지고 있습니다. 특히 웹 2.0 패러다임의 등장으로 제품/서비스 사용자의 인터넷 상의 블로그, 커뮤니티 등을 통한 적극적인 소비자의 의사표현 하는 프로슈머가 등장하였고 이들은 본인의 의견을 다른 사용자들과 적극 공유, 기업 경영에 영향력을 행사하고 있습니다. 따라서 다양한 고객의 필요 및 문제를 명확히 파악하고 이를 제품/서비스에 반영하는 것은 갈수록 치열해 지는 기업 경쟁 환경에서 기업의 생존과 직접적 관계를 가지고 있습니다.
VOC분석 시스템 주요기능
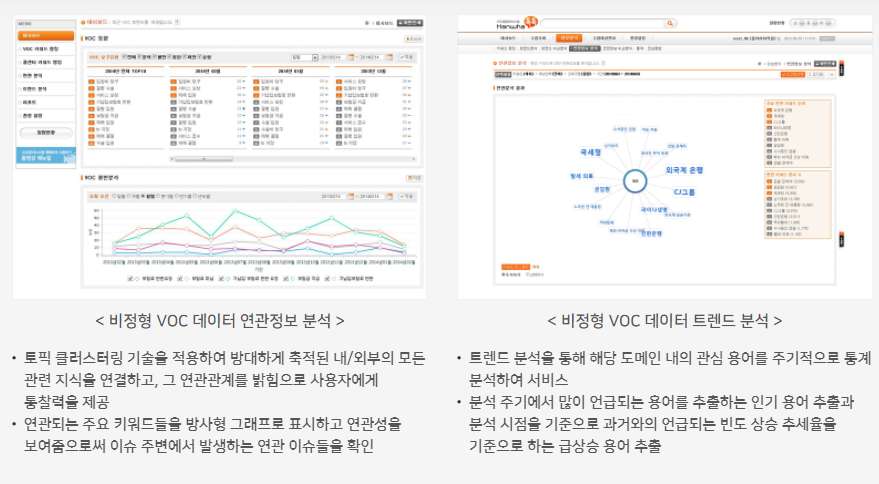
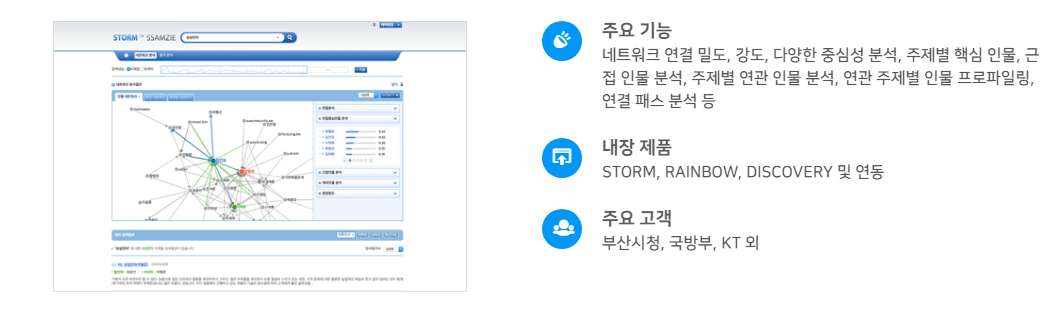
1. 연관정보 분석/트렌드 분석
토픽 랭크 기술을 적용하여 방대하게 축적된 내/외부의 모든 관련 지식을 연결하고 그 연관 관계를 제시하며, VOC 내의 관심 키워드를 주기적으로 통계 분석하여 고객 VOC 동향을 깊게 이해할 수 있습니다.
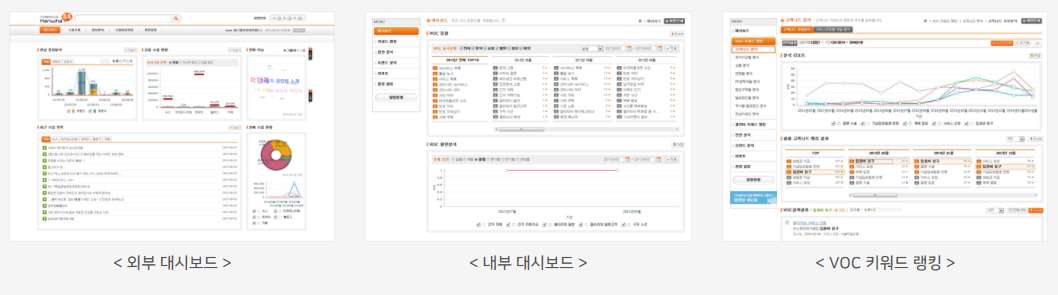
2. 통계정보 시각화
수집된 고객 상담정보에 대하여 분류별 특성정보를 다양한 통계적 방법(빈도, 추이, 다차원분석)으로 분석하고, 시각화 및 Dashboard로 제공함으로써 이슈 발생 가능성을 정량화하여 이슈 및 문제점 등에 대한 정확한 원인파악 및 대응방안을 수립할 수 있도록 지원합니다.
3. 종합 대시보드
최신 VOC 동향을 기간별, 연령별, 성별 등 다양한 유형별로 제공함으로써 한 눈에 고객의 요구를 조망할 수 있습니다.
4. 키워드 종합랭킹
종합 랭킹을 통해 지속적인 VOC 이슈를 확인할 수 있고 급상승 랭킹을 통해 새롭게 도출되는 이슈를 파악할 수 있으며 사용자가 원하는 정보에 대한 랭킹을 볼 수 있는 관심 키워드 랭킹을 제공합니다.
5. 리포트 기능
분석된 VOC에 대한 가시성 높은 통계와 다양한 유형의 리포트를 제공합니다.
6. 연관 이슈 분석
내∙외부 수집 정보(트위터, 블로그, 카페 등)에 대한 연관 이슈를 조회하고 트렌드 분석을 제공합니다.
VOC데이터의 특징
일반적으로 VOC 데이터는 다음과 같은 콘텐트적 특징을 가지고 있으며, 각 특징에 맞춰 적합한 분석 기법의 적용이 필요합니다.
VOC데이터 분석을 위한 기법
텍스트마이닝을 활용한 VOC 데이터 분석 기법과 해당 기법을 적용하기 위한 기술은 다음과 같습니다.
VOC데이터 분석의 고려사항
공공데이터 개방 LOD
오픈 데이터는 오픈 소스, 오픈 플랫폼과 더불어 IT 개방 생태계의 핵심 축으로 자리매김 하고 있습니다. 특히, 공공데이터 개방은 전세계적으로 거스를 수 없는 중요 패러다임이 되었습니다. 솔트룩스는 지난 10년간 공공데이터 개방, 검색, LOD(Linked Open Data) 플랫폼 구축을 위한 기술과 솔루션을 제공해 왔으며 국제 기구인 ODI(Open Data Institute)와의 협력을 통해 오픈 데이터 표준화, 인증 및 확산에 기여하고 있습니다. 솔트룩스의 LOD 솔루션을 통해 공공데이터 개방 최고 등급인 5성(Five Star)급 데이터 서비스를 경험하십시오.
솔트룩스의 공공데이터 개방을 위한 LOD 솔루션은 공공데이터를 위한 지식그래프 모델링과 데이터 자동 변환 및 통합을 위한 규칙 엔진, 인스턴스 자동 변환기와 대규모 저장소를 내장하고 있으며, RESTful 형식의 SPARQL EndPoint를 통해 매우 강력한 데이터 질의를 제공하고 있습니다. RAINBOW와의 연계를 통해 다양한 시각화뿐 아니라 온라인 분석 서비스 구현도 가능합니다.
주요 특징
LOD서비스 체계 구축
LOD(Linked Open Data)는 웹을 통한 데이터 개방과 유통을 위해 W3C에서 표준화한 데이터 표현, 출판 및 검색 방법입니다. LOD는 RDF 형식의 데이터 표현과 출판, REST 프로토콜과 SPARQL을 통한 검색과 질의를 제공하며 URI를 통해 모든 데이터가 연결 가능한 웹을 지향합니다. LOD에 기반한 공공 데이터 개방의 큰 특징은 인터넷 상에서 개방된 모든 데이터를 연결, 활용하고 상이한 데이터를 통합한 개방형 지식 베이스를 구현할 수 있다는 점입니다. 솔트룩스의 LOD 솔루션은 공공기관, 지자체에서의 정보 공개에 가치를 부여합니다.
솔트룩스의 LOD 구축 솔루션은 지난 10년간 국내외 주요 고객을 통해 검증된 STORM 플랫폼의 SOR과 STRANSFORMER 제품에 기반하고 있습니다. 다양한 종류의 공공데이터로부터 지식그래프 스키마를 구성하고, 원시데이터를 RDF로 변환, SPARQL EndPoint를 통해 질의, 시각화하는 것을 일괄 자동화 하는 것이 가능합니다.
솔트룩스는 검증된 LOD 솔루션을 기반으로 단편적이고 파편화된 데이터간의 의미 있는 관계 정보를 찾아 숨겨져 있는 정보를 가치 있는 지식 자산으로 활용하고, 기존의 제한적이었던 데이터 접근 방식을 누구나 쉽게 탐색하고 활용할 수 있도록 지원하며, 국내 LOD 및 오픈데이터 산업 발전의 교두보로써 그 역할을 해나갈 것입니다.
오피니언 마이닝
모바일 환경의 성숙과 소셜 미디어의 대중화는 일반 시민들의 정치, 사회, 경제에 대한 영향력을 증대시켰으며 국가 정책과 기업, 제품에 대한 개인과 소규모 집단의 의견이 결정적 영향을 주고 있습니다. 솔트룩스는 지난 20년간 한국어, 영어, 일어 등을 포함한 다국어 형태소 분석, 구문 분석, 개체명 인식, 이벤트 추출 엔진을 개발해 왔으며 이를 적용한 고품질, 고정밀 감성 분석(Sentiment Analysis)과 오피니언마이닝 솔루션을 제공하고 있습니다. 솔트룩스의 자연어 처리 및 오피니언 마이닝 기술은 기계학습(Machine Learning)과 딥러닝(Deep Learning)에 기반한 세계 최고 수준의 분석 품질을 제공하고 있습니다.
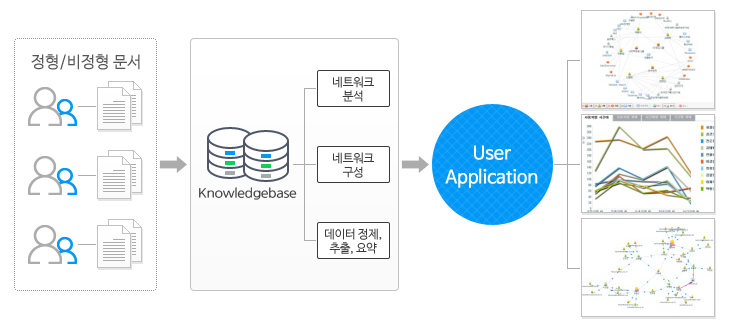
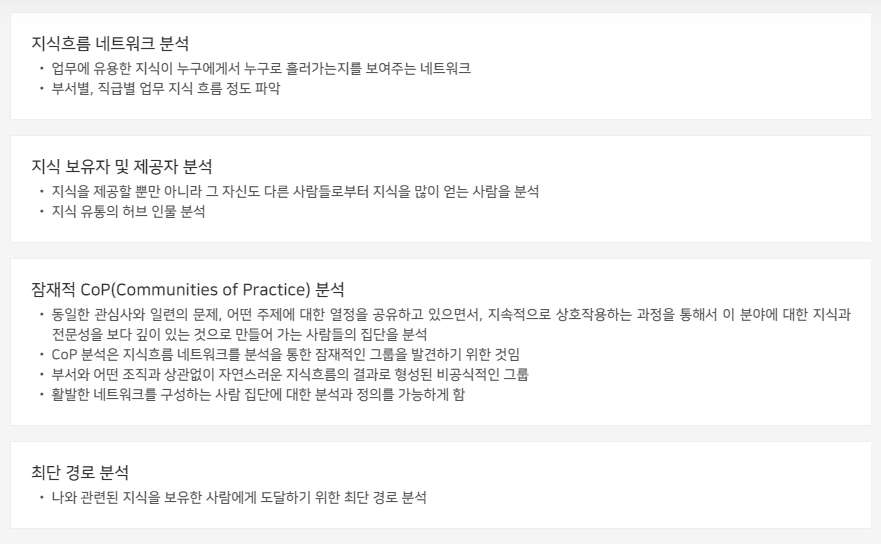
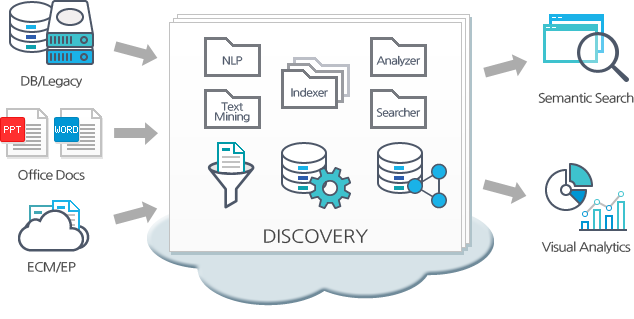
지식/소셜 네트워크 분석
인터넷과 모바일 서비스의 발전은 사람들의 연결 구조를 더욱 동적이고 복잡한 유기체로 만들고 있습니다. 사람들간의 연결 구조는 다양한 데이터와 콘텐트의 유통 경로가 될 뿐 아니라 구매 활동을 포함한 의사 결정에 많은 영향을 주고 있습니다. 솔트룩스는 지식/소셜 네트워크 분석 솔루션을 통해 소셜미디어, 이메일, 방대한 기업 문서로부터 시맨틱 소셜 네트워크를 추출해 그 구조를 분석하고, 네트워크에 흐르는 지식과 상호 영향력을 심층 분석함으로 문제 해결을 위한 전문가 검색과 추천, 마케팅 전략 도출, 지식 활동 프로파일링, 지능형 보안과 안보 분석, eDiscovery 체계 등의 구축을 가능하게 합니다.
< 지식/소셜 네트워크 분석 솔루션 구조도 >
개요
네트워크 분석은 그래프 이론(graph theory)을 이용하여 객체(행위자를 포함한 모든 객체)간의 관계를 분석하는 정량적인 분석방법론으로 분석 대상에 따른 다양한 분석방법이 있으며, 대표적으로 사회관계분석(social network analysis)이 있다. 현재 조직에서는 지식의 흐름과 유통에 대한 분석을 통해 지식의 새로운 가치를 발견하거나 업무나 회사 운영에 활용하기 위한 많은 노력을 하고 있습니다. 조직 내에는 다양한 정보들(문서, 이메일, 웹 등)를 보유하고 있으며, 이들 정보자원에 대한 분석을 통해 지식네트워크를 구성할 수 있습니다. 일반적으로 조직에서 지식네트워크를 하게 되면 다음과 같은 이점을 얻을 수 있습니다. 이와 같이, 지식네트워크 구성은 조직 내 분산되어 있는 지식에 대한 통합, 지식 유통 경로, 지식 흐름, 사용자 유형 분석 등을 위한 기초를 제공합니다.
주요특징
상세 기능
지식네트워크는 조직 내에서 발생하는 다양한 주제정보 네트워크 및 사회관계 네트워크에 기반하고 있으며, 지식네트워크 분석은 구성된 주제 및 사회관계에 대한 분석을 통해 지식 중개자, 지식 전문가 정보를 제공할 뿐만 아니라, 지식의 유통경로나 지식 흐름 경로 분석, 사용자 유형 분석 결과를 제공할 수 있습니다. 조직 내의 지식 분석을 위한 데이터 소스(Data Source)와 이를 통해 가능한 분석 방법은 다음과 같습니다.
조직 내에 구성된 지식네트워크는 관점에 따른 다양한 분석과 활용이 가능하며, 이를 통해 조직 내에 분포되어 있는 지식에 쉽게 접근하거나 활용할 수 있는 기초를 제공할 수 있습니다. 이와 같이, 지식네트워크 분석은 다음과 같은 특징을 가지게 됩니다.
지식네트워크 활용
조직이 보유하고 있는 정보로부터 지식네트워크를 구성하고 이를 어떻게 활용할 것인지를 지식네트워크 특징을 중심으로 설명해보겠습니다. 기본적으로 조직은 이메일 시스템을 통해 조직 내의 다양한 업무 정보를 공유합니다. 조직 내에서 활용하고 있는 이메일 시스템과 같이 네트워크 구성이 가능한 데이터 소스에 대한 분석을 통해 구성된 네트워크를 어떻게 업무에 적용할 것인지를 살펴보면 다음과 같습니다. 전제조건은 이메일 기반 네트워크는 이메일 발/수신을 중심으로 구성되며, 지식 흐름은 네트워크상에 존재하는 개체분석을 통해 지식네트워크를 구성합니다. 활용방법을 살펴보면 다음과 같습니다.
조직 내에서 네트워크는 관점에 따라 조직 구성원에 대한 감시와 같은 개인 프라이버시와 같은 문제를 야기 시킬 수 있는 반면, 조직 내의 다양한 지식 계층을 발굴함으로써 얻는 이점이 더 많다고 할 수 있습니다.
특장점
지식네트워크는 조직 내에서 발생하는 다양한 주제정보 네트워크 및 사회관계 네트워크에 기반하고 있으며, 지식네트워크 분석은 구성된 주제 및 사회관계에 대한 분석을 통해 지식 중개자, 지식 전문가 정보를 제공할 뿐만 아니라, 지식의 유통경로나 지식 흐름 경로 분석, 사용자 유형 분석 결과를 제공할 수 있습니다. 조직 내의 지식 분석을 위한 데이터 소스(Data Source)와 이를 통해 가능한 분석 방법은 다음과 같습니다.
콘텐츠 맞춤 추천 및 개인화
동영상을 포함한 사용자 제작 콘텐트의 생산량이 크게 증가하고 그 유통 구조가 다양해 짐에 따라 원하는 콘텐트를 쉽게 발견하고 소비하기가 점점 어려워 지고 있습니다. 솔트룩스의 사용자 맞춤형 콘텐트 추천 및 개인화 솔루션은 사용자의 선호를 의미적으로 분석하고 각 사용자에게 적합한 콘텐트 만을 지능적으로 추천할 수 있는 솔루션입니다.
신기술 분석, 센싱, 예측 솔루션
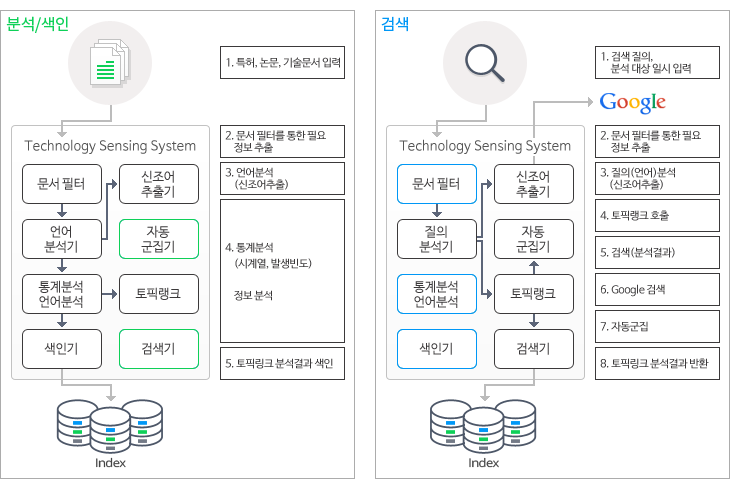
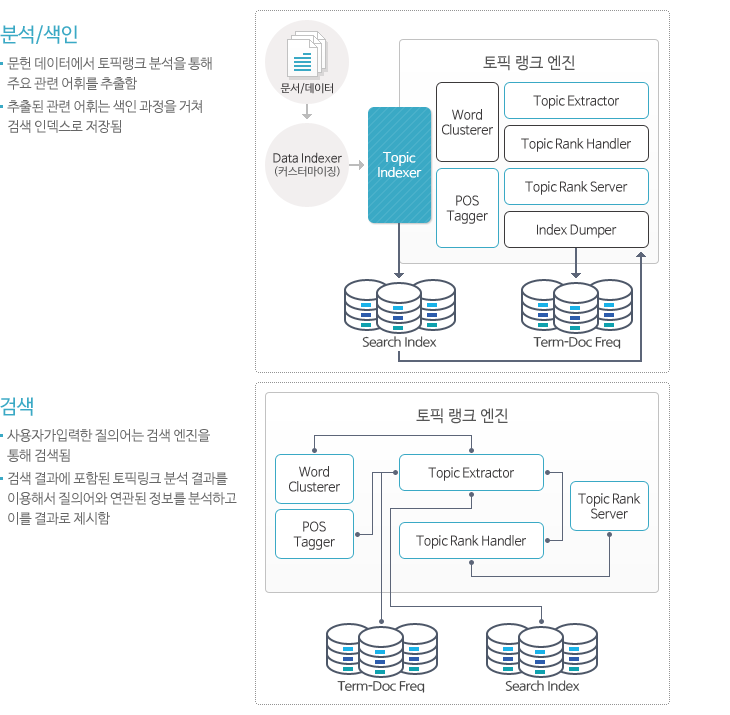
치열한 글로벌 경쟁에서 살아남기 위해 기업들의 R&D 투자는 크게 늘어 났지만, 그 성과는 오히려 줄어들고 있습니다. 이제는 경험과 직감에 기반한 기술 개발이 아닌 데이터 분석과 시장, 기술 예측을 통한 합리적이고 현명한 연구 개발 정책 수립과 투자가 필요한 시기입니다. 세계적 글로벌 기업들과 공공 기관을 통해 검증된 솔트룩스의 신기술 분석, 기술 센싱 및 예측 솔루션을 경험해 보십시오.
개요
최근 웹 영역에서 생성되는 다양한 형태의 Contents들은 기하급수적으로 증가하고 있습니다. 이렇게 수많은 Contents 들 중에서 원하는 정보를 찾을 방법은 검색엔진 혹은 검색기술을 통해 개별 지식을 발견하는 것입니다. 그러나 발견된 정보가 세상 혹은 웹 영역에서 어떠한 정보량과 시계열적 의미가 있는지를 알아내기는 매우 어렵습니다.
Google은 ‘구글 트렌드’ 라고 하는 검색 질의랭킹 분석 서비스를 통해 트렌드 분석을 제공하고 있으나 검색 시스템에 질의된 검색어를 통계적으로 분석한 인기검색어 기능을 응용하여 표현한 한계를 가지고 있습니다. 트렌드 분석은 웹 또는 도메인 내에서 생성되는 Contents 들을 분석해 특정 지식의 연관관계를 제시하거나 발생 경향을 분석함으로 단편적인 지식발견이 아닌 생성/활용/트렌드를 분석할 수 있는 기능이있습니다. 트렌드 분석 기능은 웹에서 발생하는 웹페이지, 블로그, 트윗, 각종 게시판 Contents를 분석하여 사회적인 이슈나 세상에 회자되는 관심사항을 자동으로 분석하는 용도로도 사용할 수 있지만, 기업활동 영역 내에서 생성되는 고급 Contents의 분석에도 효과적으로 사용될 수 있으며 그 가치는 수익활동과 연결될 수 있는 ROI를 제공합니다.
목적
기업활동에 수반되는 문서의 형태는 다양하나 그중에서 기술과 관련된 지식은 기업이 영속할 수 있는 핵심내용을 담고 있습니다. 내부에서 생성되는 지식뿐 아니라 외부에서 생성되고 수집되는 기술문서 역시 관리되어야 할 중요한 내용으로 최근 들어 특허관리 및 융합기술이 특히 중요해 지고 있습니다. 그러나 기술문서 역시 지식활동에 따라 대량으로 발생하고 있어 모든 내용을 검토하거나 분석하는 것이 어렵습니다. 텍스트마이닝 기술은 이런 환경에서 특허, 논문, 지식문서 등의 기술 문헌에 대한 트렌드 분석을 수행할 수 있는 유용한 기술입니다.
신기술 센싱은 지능적 분석을 통해 미래 R&D 기술에 대한 트렌드를 파악하고, 제품의 연구/개발 의사결정에 도움을 주는 역할을 합니다. 기업에서 신기술 혹은 신제품 개발 등의 연구개발 추진 시 사전 특허 조사, 기술 등의 R&D 동향 분석은 필수적입니다. R&D 종사자에게는 세부 기술 수준에서의 동종/이종 기술 간의 융합패턴 발견이 중요하며, 개별 제품 레벨에서의 이 제품에 적용될 수 있는 미래 기술 및 미래 시장 제품의 발견 중요성이 증대되고 있습니다. 신기술 센싱은 통시적 분석과 공시적 분석을 수행하며 이 기능들은 각각 기술들 간의 연관관계 분석과 부상기술 분석, 기술 트렌드 기능을 제공합니다.
시스템 구성
센싱 시스템은 배치형태의 분석, 색인 과정과 서비스를 위한 검색과정으로 구분됩니다. 특히 분석은 두 가지 분석을 수행하게 되며, 통시적 분석은 통계분석 및 회귀분석을 사용하고, 공시적 분석은 토픽랭크 알고리즘을 통해 이루어집니다.
공시적 현상 분석은 사용자가 입력한 질의어에 기반을 두어 검색하고, 검색 결과 문서의 키워드 벡터를 토픽랭크 분석하여 키워드의 관계 네트워크 정보를 제시합니다.
통시적인 현상 분석은 주기적으로 입력받은 문헌 정보를 단위 시간대별로 나눠 분석하고 이 분석 결과에 기반을 두어 해당 단위 시간대에 중요하게 증가/변화되고 있는 기술 용어를 순위별로 제시합니다.
결론
기술 선진국일수록 기업 자체적으로 구축한 풍부한 R&D 노하우 및 자사 특허 포트폴리오를 바탕으로 미래 기술을 예측한 후 R&D 방향을 결정합니다. 트렌드 분석 (기술센싱) 시스템은 미래의 불확실성에 대한 의사결정 가이드를 제공하며 주요 관심 사항에 대한 집중적인 검토 계기를 제공할 수 있습니다. 트렌드 분석 시스템이 제공하는 기능들은 방대한 내외부 기술 문헌을 효율적으로 자산화할 수 있는 임무을 수행합니다.
IoT 대응 상황인지 솔루션
웨어러블 디바이스를 필두로 스마트 시티와 스마트 홈, 헬스케어와 에너지 IoT 등 센서 네트워크 기반의 혁신적 서비스들이 다가오고 있습니다. IoT 혁신은 실시간 스트림 빅데이터에 대한 지능화와 상황인지 서비스 구현에 승패가 달려있습니다. 솔트룩스는 지난 10년간 실시간 센서 데이터의 지능화와 의미기반 상황인지 기술을 개발 및 공급해 왔으며 다양한 상용화 실적을 보유하고 있습니다.
지능형 감사/보안
활용 가치가 큰 빅데이터의 80%가 위치와 관련 있는 지리공간 빅데이터라는 통계가 있을 정도로 위치 기반한 빅데이터 분석은 매우 중요합니다. 솔트룩스는 의미기반 지리공간 모델링과 GIS 연동 가능한 빅데이터 융합 분석 솔루션을 제공하고 있으며, 소셜 빅데이터와의 연계를 통한 지역별 이슈 및 평판 분석, 실시간 마케팅 분석과 이상징후 조기 감지 등의 심층 분석을 지원합니다.
개 요
지리공간정보의 시맨틱 활용은 지리적 특징, 지리기하학적 특징, 지리인문학적 특징 등과 같은 지리와 관련한 다양한 계층의 데이터들이 위치좌표를 중심으로 연계되고 추론 처리하여 새로운 지리정보를 제공할 수 있는 활용사례들입니다.
지리공간정보
지리공간정보는 위치좌표를 가진 지리적 정보를 바탕으로 지형학, 생물학, 유전병학, 사회학, 인구통계학, 통계학 등의 연관 정보를 가진 정보입니다. 위치좌표는 이동형 단말장치의 센서정보를 이용하여 수집된 WGS84 좌표정보입니다. WGS84는 구체의 중심으로부터 지구표면에 대해 위도, 경도로 표시됩니다.
시맨틱 기술
시맨틱 기술은 데이터에 대해 사람과 기계가 이해하고 공유 및 추론할 수 있게 하는 기술입니다. 이를 위해서는 프로그램들 간 공유하는 데이터 집합이 가진 데이터들 간에 관계를 추가, 변경하고 상호 연계시킬 수 있도록 데이터 모델링을 합니다.
데이터 모델링은 데이터의 개념을 체계화하고 개념들 간의 관계를 정의하고 관계에 해당하는 실체들을 정의합니다. 이는 웹상의 자원들을 표현하는 RDF를 기반으로 온톨로지로 나타냅니다. 온톨로지를 저장하는 시맨틱 저장소는 RDF의 형태로 저장하며 Subject, Predicate, Object의 하나의 트리플 형태로 문장 단위로 저장합니다.
프로그램이 처리를 위해 필요로 하는 데이터를 시맨틱 저장소에서 질의를 하기 위해 SPARQL이라는 질의언어를 사용하여 질의를 수행합니다. 질의 내용 중 지식그래프 내에 표현된 데이터들의 관계성에 따라 값이 지정되지 않은 질의 내 변수는 추론기의 추론을 통해 변수 값을 조회해볼 수 있습니다.
추론처리는 개념과 속성들의 상하관계의 정의에 따른 규칙인 Axiom 기반 추론과 개념 및 속성을 SWRL 규칙언어를 이용하여 정의하여 규칙에 맞는 값을 찾아내는 Rule 기반 추론이 있습니다.다. 또한 데이터의 관계들을 미리 추론하는 Forward chaining 추론과 데이터들이 자주 변경되어 질의 시 추론 처리되는 Backward chaining 추론이 있습니다.
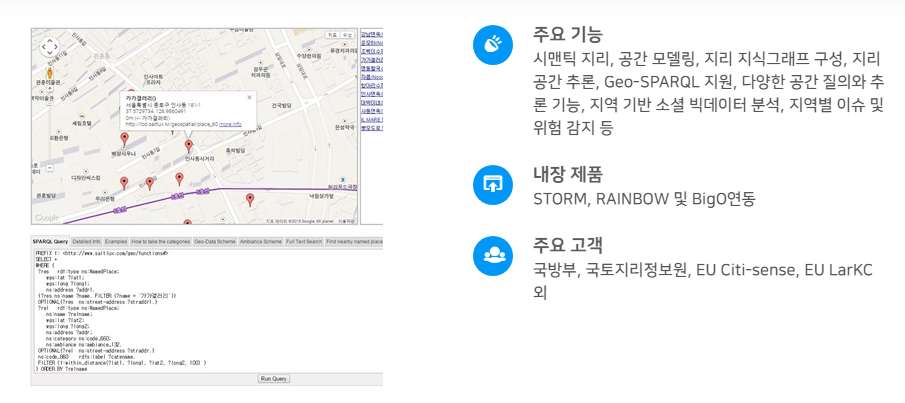
적용 사례
솔트룩스는 지리정보 Open Street Map(www.openstreetmap.org), 서울지역 Point Of Interest(POI)와 건설기술연구원의 서울범위 도로표지판을 바탕으로 온톨로지를 모델링하고 데이터 처리 및 응용처리를 위한 추론 처리결과를 보여주는 서울 도로교통표지판 관리시스템을 구축하였습니다.
동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
클라우드 서비스 Cloud Service
Cloud 기반 지능형 서비스 및 데이터 산업 패러다임 변화
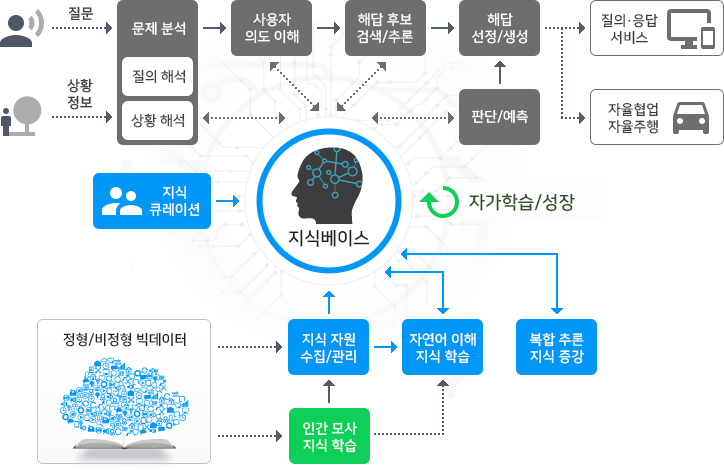
클라우드컴퓨팅의 초기 목적이 IT 관리 효율화였다면 4차 산업혁명이 진행되면서 그 목적이 빅데이터 분석과 인공지능 개발로 변화되고 있습니다. 빅데이터는 모든 산업의 발전과 새로운 가치 창출의 촉매 역할을 하고 있으며 이러한 패러다임 전환은 IT(Information Technology) 시대에서 DT(Data Technology) 시대로 이끌었습니다. 1950년대부터 관련 연구가 시작되어 발전해 온 인공지능은 기술적 한계에 부딪히며 한동안 침체를 겪어왔으나 고속 병렬 처리가 가능한 클라우드 컴퓨팅의 등장으로 대용량 딥러닝 연산 소요 시간이 대폭으로 단축되어 지능형 서비스에도 활발히 적용되고 있습니다.
하지만 DT시대에서 빅데이터의 수집, 저장, 분석을 위한 방대한 컴퓨팅자원과 인공지능 개발을 위한 슈퍼컴퓨터를 개별기업이 자체적으로 구비하는 것은 현실적이지 않습니다. 특히 자본력이 부족한 중소기업이나 스타트업은 4차 산업혁명 실행을 위한 대규모 컴퓨팅자원을 저렴하게 활용할 방법이 필요하였으며 클라우드를 통해 대규모 컴퓨팅자원을 저렴하게 활용할 수 있게 되었습니다. 이러한 이유로 4차 산업혁명이 진행될수록 클라우드서비스의 역할이 중요해지고 있습니다.
시장 변화에 따른 제품 서비스 혁신의 통찰력
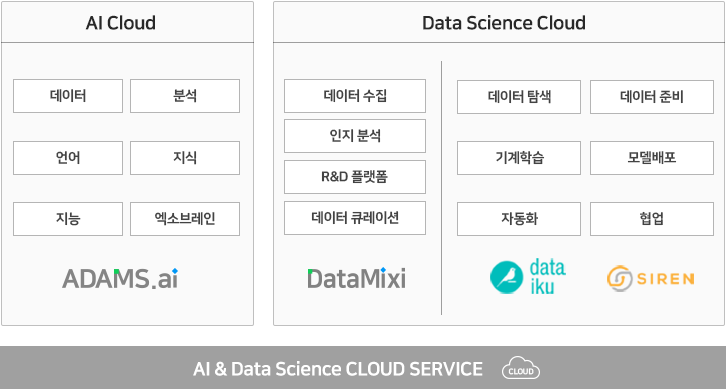
빅데이터 분석과 지능형 서비스의 특성에 따라 클라우드는 필수 불가결한 수단이며 솔트룩스는 이러한 시장의 변화에 대하여 선제적으로 대응하고 있습니다. 4차 산업혁명 시대의 데이터 경제 패러다임 변화를 이끌기 위하여 오래전부터 데이터를 지식화(스마트 데이터)하여 제대로 활용하기 위하여 AI & Big Data 기술을 융합한 인공지능(AI) 클라우드서비스와 데이터사이언스 클라우드서비스를 출시하였습니다.
데이터사이언스 클라우드서비스는 인공지능과 데이터 과학자를 위한 국내 유일의 데이터사이언스포털(DATAMIXI.com)입니다. 데이터 분석을 위한 통찰과 인공지능이 결합한 인지분석으로 데이터를 융합하여 심층 분석하고 다양한 관점에서 시각화함으로써 데이터 간의 숨겨진 패턴을 발견하고 미래를 예측할 수 있습니다.
소개
솔트룩스 Cloud Service는 인공지능 서비스 개발자, 데이터 과학자, 데이터 분석가, 금융거래 이상징후 분석 담당자와 같은 사용자 모델을 대상으로 다양한 산업영역에 적용 가능한 인공지능 서비스를 제공합니다.
< 클라우드 서비스 개념도 >
솔트룩스 Cloud Service는 두 가지 서비스로 구성되어 있습니다. 1) AI Cloud(ADAMS.ai) 서비스는 솔트룩스가 지난 20년간 자연언어처리와 시맨틱, 추론을 포함한 인공지능 원천기술을 바탕으로 개발된 언어지능, 시각지능, 감성지능, 학습/추론 지능을 인공지능 서비스 개발에 필요한 API 형태로 제공하는 클라우드서비스입니다. 2) Data Science Cloud(DATAMIXI.com)는 ADAMs.ai가 미리 학습된 일반 도메인 모델을 웹 서비스로 노출한 오픈 API의 특성을 갖는 데 반하여, 고객이 보유한 도메인 데이터셋을 이용하여 새로운 모델을 학습하고 서비스에 반영할 수 있도록 기계학습 워크플로우 서비스 및 지능형 빅데이터 인지 분석 서비스를 제공합니다.
주요 특성
< Cloud Service 특성 >
주요 경쟁력
< 솔트룩스 클라우드서비스 기반기술의 차별성 >
클라우드 서비스 Cloud Service 상세
3세대 AI 클라우드 서비스
솔트룩스의 ‘AI 클라우드’는 ADAMS.ai 라는 이름으로 2017년 대한민국 최초로 상용화된 인공지능 클라우드 서비스(AI as a Service) 입니다. 이제 그 이름을 ‘솔트룩스 AI 클라우드’로 서비스 명을 변경하고, 기존의 Open APIs 기반의 AI 서비스에서 맞춤형 AI PaaS 서비스 플랫폼으로 새롭게 출발을 합니다.
다양한 인공지능 기술이 연구개발 되도 실제 사업화, 현장 적용에 실패하는 경우가 많습니다. 인공지능 기술의 성능은 ‘학습 데이터’에 크게 의존하고 있고, 일반 도메인에서 99%의 성능을 보여도, 실제 문제 해결 현장에 적용 하면 50% 수준으로 품질이 낮아지게 됩니다.
이런 이유로, 솔트룩스는 국내 유일하게 (1) 각 도메인에 학습 최적화, 적응이 가능한 ‘커스텀‘ AI 서비스와 (2) 서비스 사업자(개발자)의 요청에 따라 신규 개발, 클라우드에 배포 가능한 ‘온디맨드’ AI 서비스를 제공하고 있습니다. 공통 Open API로는 실제 인공지능 상용 서비스와 시스템 구현이 어렵습니다. 이제 솔트룩스의 커스텀 AI 서비스와 온디맨드 AI 서비스를 통해 성공적 AI 사업을 추진해 보세요.
쿠버네티스 기반의 멀티 클라우드 확장성
솔트룩스의 AI 클라우드는 쿠버네티스와 콘테이너(도커) 기반의 AI 서비스와 커스텀 모델 배포, 관리 체계를 제공하고 있습니다. 무료 Open APIs 서비스는 자체 IaaS를 사용하고 있으며, 커스텀 및 온 디맨드 AI 서비스는 사용자 (개발자)가 솔트룩스의 IaaS 혹은, 마이크로소프트(Azure), 아마존(AWS)을 운영 정책과 가격 등에 따라 선택할 수 있습니다. 필요에 따라서는 여러 IaaS를 연결 융합해서 사용, 확장할 수도 있습니다.
Data Science Cloud Service(DataMixi.com)
Data Science Cloud Service - DATAMIXI는 데이터 과학자를 위하여 지능형 데이터 분석을 위한 통찰과 인공지능이 결합한 인지분석 서비스로 데이터를 융합하여 심층 분석하고 다양한 관점에서 시각화함으로써 데이터 간의 숨겨진 패턴을 발견하고 미래를 예측할 수 있는 국내 유일의 데이터 과학자들을 위한 포털 서비스입니다. 데이터 과학자나 인공지능 기반 데이터 분석 서비스를 매시업 (mashup) 방식으로 프로젝트에 통합하고자 하는 IT 엔지니어, 개발자들을 위해 기획된 데이터 과학 컨설팅 서비스입니다.
< Data Science Cloud Service - DATAMIXI >
Data Science Cloud Service - DATAMIXI는 데이터사이언스, 데이터 큐레이션, 인지분석 서비스로 구성되어 있습니다. 데이터사이언스는 빅데이터구축에서 분석 및 활용까지의 전 과정을 지원하는 클라우드서비스에 대한 명칭입니다. 데이터 큐레이션은 솔트룩스 데이터구축-분석 프로세스를 특징짓는 <Human-in-the-loop>를 통해서 데이터구축자와 소프트웨어 시스템이 협업할 수 있는 구조를 통칭합니다. 인지분석 서비스는 트렌드 분석, 감성분석, 시각화 서비스로 구성되어 있으며 수백억 단위의 인스턴스로 이루어진 데이터셋을 바탕으로 분석 및 시각화 서비스를 제공합니다.
주요 특징
인공지능과 데이터 과학자를 위한 국내유일의 데이터 과학 포털 DATAMIXI는 데이터 분석을 위한 통찰과 인공지능이 결합된 인지분석으로 데이터를 융합하여 심층 분석하고 다양한 관점에서 시각화 함으로써 데이터 간의 숨겨진 패턴을 발견하고 미래를 예측할 수 있습니다.
주요 서비스
데이터사이언스 서비스
솔트룩스의 데이터사이언스 서비스는 지난 20년 동안 축적된 인지분석과 기계학습의 성공 경험과 전문가(데이터 과학자)들의 참여를 통해 데이터 수집, 정제에서 시작해 기계학습 및 분석 모델의 선정과 최적화, 예측과 지능화 결과에 대한 평가와 시각화에 이르는 전주기에 대한 실무에 바로 적용 가능한 IT 실무 지식과 기술교육 등을 제공하는 컨설팅 및 교육 서비스입니다.
< 데이터 사이언스 서비스 >
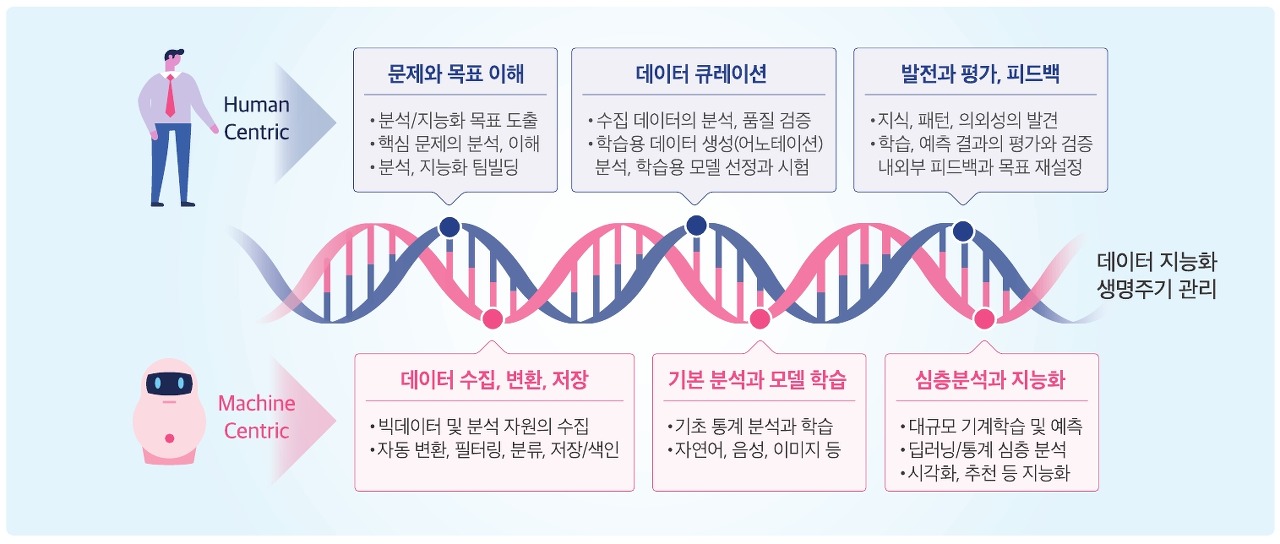
Data Science Cloud Service - DATAMIXI의 데이터사이언스 서비스는 컴퓨터공학, 수리통계학, 데이터 모델링, 기계학습 알고리즘, 도메인 지식 모델링 기법이 솔트룩스만의 이중나선 방법론을 통해 융합되어 지능형 빅데이터 분석 서비스, 질의응답이나 대화 서비스와 같은 인공지능 기반 지식서비스 개발로 이어집니다.
< 이중나선 방법론 기반의 데이터 서비스 >
탁월한 수준의 심층 데이터 분석과 서비스 지능화를 위해서는 사람과 기계의 적극적인 협력(human-in-the-loop)이 필요합니다. DATAMIXI의 데이터사이언스 체계는 알고리즘/도구와 전문가가 적극적으로 상호 협력하는 이중나선 방법론(dual spiral methodology)에 기반하고 있습니다.
전형적 데이터사이언스의 절차는 솔트룩스만의 이중나선 방법론을 적용하여 데이터 수집, 정제에서 시작해 기계학습 및 분석 모델의 선정과 최적화, 예측과 지능화 결과에 대한 평가와 시각화 과정이 반복적으로 수행됩니다.
< 데이터 사이언스 컨설팅 서비스 절차 >
① 요구 사항 분석 단계
고객이 요구하는 데이터 분석에 대하여 분석/지능화 목표 도출, 핵심 문제의 분석 및 이해를 통하여 데이터 분석에 필요한 데이터 자원들을 정의 및 방향성을 도출하는 단계입니다.
② 데이터 큐레이션 단계
심층 분석과 기계학습 수행 시의 가장 큰 고충은 오류를 포함한 대규모 데이터에 대한 정제와 학습 데이터의 부족에 있습니다. 데이터 큐레이션은 요구사항 단계에서 정의되어진 데이터 자원을 수집하고 각 분석과 지능화 목적에 부합되는 프로세스와 도구 그리고 훈련된 전문가를 통해 데이터를 정제필터링을 통해 분석 및 학습을 위한 데이터를 생산하는 단계입니다.
③ 데이터 분석 및 학습 단계
전통적 통계 분석 뿐 아니라 CRF와 SVM과 같은 다양한 기계학습 기술과 CNN, RNN과 같은 심층신경망 기반의 딥러닝 기술을 활용한 데이터 심층 분석을 수행하는 단계입니다. 솔트룩스의 다양한 분석 엔진들과 R, TensorFlow와 같은 강력한 오픈소스를 융합한 지능형 분석 플랫폼을 활용하여 대규모의 데이터의 기계학습 및 예측, 딥러링 기반의 심층분석 등을 수행하며, 모델의 검증, 평가, 모델 매개변수 튜닝. 학습 알고리즘 변경 등을 통해 고객의 요구사항에 부합되는 최적을 분석 결과를 도출해 내는 과정입니다.
④ 데이터 분석 검증 및 피드백 단계
고객에게 분석 결과를 전달하기 전 분석되어진 결과에 대하여 지식, 패턴, 예외를 발견하거나 내·외부 전문가 및 고객의 피드백을 통하여 학습·예측 분석 결과의 평가, 검증을 받는 단계입니다.
⑤ 데이터 분석 최종 보고 단계
데이터의 분석과 활용이 개인과 조직의 새로운 힘이 되고 경쟁력이 될 수 있는 고객의 요구사항에 부합하는 데이터 분석 결과보고서 제공 단계입니다.
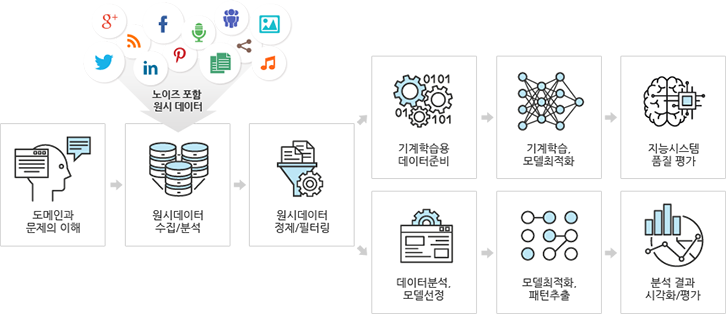
데이터 큐레이션 서비스
데이터 수집과 정제에서 메타정보태깅(annotation)과 분류, 학습용 데이터 생성 등 데이터의 활용 가치를 높이기 위한 모든 활동을 의미합니다. 데이터 기반의 심층 분석과 기계학습을 위해서는 대규모 데이터의 확보뿐 아니라 기계가 읽고, 학습하고, 의미 이해 가능한 형태로 가공되어야 합니다. 솔트룩스의 데이터 큐레이션 서비스는 솔트룩스 20년의 데이터 품질관리와 기계학습 경험이 축적된 세계 최고 수준의 데이터 서비스를 제공합니다.
< 데이터 큐레이션 서비스 >
① 데이터 큐레이션 서비스 절차
데이터 큐레이션의 6단계는 모든 도메인에 공통적으로 적용되며, 각 단계별 전문가 팀이 고객의 지식서비스 구축을 위해 유기적으로 협업하게 됩니다.
② 데이터 큐레이션 서비스 기능
데이터 큐레이션은 데이터의 활용 가치를 높이는 모든 활동을 의미합니다. 도서 등의 데이터 디지털화, 원시 데이터 수집, 데이터 정제 등 일반 데이터 가공 분야 외에 아래와 같이 이미지&동영상 어노테이션, R&D 데이터 어노테이션, 지식베이스 구축 등 전문 데이터 큐레이션 서비스를 제공합니다.
지능형 인지분석 서비스
솔트룩스의 지능형 인지 분석 서비스는 무료로 제공되는 약 100억 건 이상의 소셜 데이터를 활용하여 인공지능 기술이 적용된 융합분석, 연관주제 분석, 감성 분석, 트렌드 분석, 이슈 감지, 실시간 R 연동을 통한 고급 분석 기능과 데이터 속의 의미관계망 분석 기능을 통해 심층 분석을 할 수 있는 지능형 인지 분석 기능을 무료로 제공하고 있습니다.
1) 데이터 서비스에서 제공하는 다양한 공공 데이터와 내 데이터를 직접 업로드하여 등록하고 사용할 수 있는 데이터 기능
2) 두 개 이상의 파일에서 원하는 요소들만 선택하고 병합하여 원하는 분석에 최적화된 데이터를 만들 수 있는 데이터 병합 기능
3) 제공하는 소셜 데이터를 이용하여 관심 있는 분석 주제에 대한 지능형 분석을 통하여 다양한 차트를 적용해 위젯으로 만들 수 있는 위젯 생성 기능
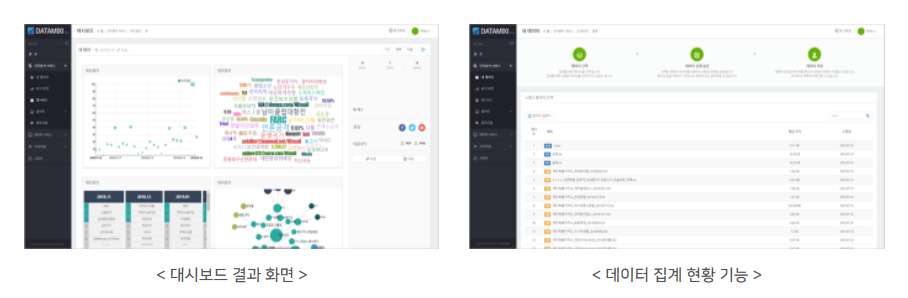
4) 생성한 위젯들을 간단하게 드래그 앤 드롭 방식으로 원하는 위치에 배치하여 나만의 대시보드를 생성할 수 있는 대시보드 생성 기능
5) 다양한 사람들의 시각으로 만들어진 대시보드를 갤러리를 통해 공유하거나 SNS를 사용하여 공유 할 수 있는 웹 공유 및 퍼블리싱 기능
① 내 데이터 기능
인지 분석 서비스에서 내 데이터 기능은 솔트룩스에서 제공하는 약 100건 이상의 소셜 데이터와 34만 건의 오픈 데이터를 활용하거나, 사용자 필요에 의한 사용자 데이터를 지능형 인지분석 서비스에서 활용하기 위하여 분석에 적합한 CSV 파일 혹은 엑셀 파일 형태로 가공하여 저장 및 등록 할 수 있는 기능입니다.
② 분석 위젯 기능
인지 분석 서비스에서 분석 위젯 기능은 솔트룩스에서 제공하는 약 100건 이상의 소셜 데이터와 34만 건의 오픈 데이터를 활용하거나, 사용자 필요에 의한 사용자 데이터를 활용하여 지능형 인지 분석을 하는 기능으로, 사용자 분석 주제에 대하여 지능형 인지 분석 기능을 활용하여 분석 결과를 다양한 차트에 적용할 수 있으며 이를 사용자 위젯으로 생성할 수 있습니다. 크게 소셜 빅데이터를 활용한 인지 분석 기능과, 내 데이터를 활용한 인지 분석 기능으로 나뉠 수 있으며, 상세 인지 분석 기능으로 트렌드 분석, 연관어 분석, 감성 분석을 할 수 있습니다.
③ 사용자 대시보드 및 갤러리 기능
사용자 인지 분석 결과 위젯은 분석 위젯 갤러리에 저장 및 등록을 할 수 있으며, 이렇게 등록된 인지 분석 결과 위젯을 활용하여 사용자는 대시보드를 생성할 수 있습니다. 생성된 대시보드는 사용자 대시보드 갤러리에 저장 및 등록을 할 수 있으며, 사용자 선택에 의하여 다른 사용자에게 공유 및 다운로드가 가능한 기능입니다.
데이터 처리 및 기계학습 기능 서비스 - Dataiku
중앙화된 데이터 기반 지능형 빅데이터 플랫폼으로서 비즈니스가 데이터를 단지 저장하는 수준에서 머무르지 않고 기업의 프로세스와 긴밀한 영향을 갖도록 분석 기능을 최대한 활용합니다. 이를 통해 데이터가 머신러닝 과정을 통해 모델화되고 기업 운영에 적용되는 단계까지 지원합니다.
< Data Science Cloud Service - Dataiku >
① 데이터 탐색 기능
데이터 세트에 대한 자동 보고서를 작성하고 잠재적인 데이터 품질 문제를 지적합니다. 단일 데이터 및 다 변수 통계를 생성하여 세부 데이터 집합 감사 보고서를 생성합니다. Excel에서처럼 쉽게 데이터를 필터링 하고 검색합니다. Spark, Hadoop 또는 SQL 엔진에서의 실행을 통해 분석범위를 확장하여 통찰력을 확보합니다.
② 데이터 전처리 및 시각적 변환 기능
코드가 없는 데이터 논쟁을 막기 위해 80개 이상의 내장형 비주얼 프로세서에 쉽게 액세스 할 수 있습니다. 자동으로 제안된 문맥 변환 및 데이터에 대한 대량 작업 수행이 가능합니다.
③ 기계학습 기능
모델의 모든 종류의 데이터를 사용하는 자동 엔지니어링, 생성 및 선택이 가능합니다. 다양한 교차 유효성 검사 전략을 사용하여 모델 하이퍼 매개 변수를 최적화합니다. 모델에서 즉각적인 시각적 통찰력을 얻고(변수 중요성, 상호 작용 또는 매개 변수 특징) 상세한 메트릭을 통해 모델 성능을 평가할 수 있습니다.
④ 기계학습 기반 모델 배포 기능
분석가와 데이터 과학자가 몇 번의 클릭만으로 생산에 모델을 배치할 수 있도록 지원합니다. 데이터 정리, 풍부화, 전처리가 함께 묶여 단순화된 채점 파이프 라인이 됩니다. 배포된 모델은 버전 관리되므로 사용자는 언제든지 새 버전을 배포하고 비교하고 롤백 할 수 있습니다.
⑤ 데이터 생성 정보 관리 기능
단일 UI 내에서 데이터 생산에 필요한 1)데이터 생성 모델(워크플로우) 개발, 2)모델 및 생산 데이터 테스트, 3)데이터 시제품(생산 전 검증), 4)데이터 제품화(데이터 및 생성 모델 패키징)에 이르는 데이터 생성에 필요한 모든 단계를 포함하고 있는 배포 모델을 제공합니다.
주요 경쟁력
주요 서비스 화면
클라우드 서비스 Cloud Service 적용사례
AI Cloud Service
T 기가 지니(GIGA Genie)와 ADAMs.ai 연계
최근 AI(인공지능) 기술을 일상에서 손쉽게 경험할 수 있게 하는 ‘AI 스피커’가 전 세계적으로 잇따라 출시되고 있습니다. 2014년 아마존이 자사 AI 비서 알렉사를 기반으로 출시한 ‘에코’를 시초로 세계적으로 관련 시장이 가파르게 성장하고 있습니다.
국내에서는 KT, SK텔레콤, LG유플러스의 통신사 3곳이 AI 스피커 시장을 견인하고 있으며, 글로벌 인터넷 기업들이 견인하는 북미 등 주요 국가보다는 태동이 늦었지만 가파르게 성장하고 있습니다. 그 중에서 KT는 가입자 150만 명에 달하는 국내 AI(인공지능) 스피커 시장 1위 기업이며, 2017년 1월 AI 스피커 ‘기가지니’를 출시한 이후, 기가지니 LTE, 기가지니 버디, 기가지니2, AI메이커스키드 등 제품군을 다각화하고 있습니다.
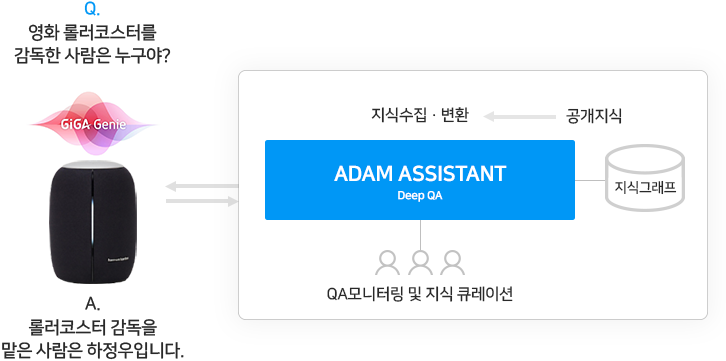
기가지니는 KT의 각 홈 서비스 플랫폼 (IPTV, 음악, 통화, 홈 IoT)과 밀결합하여 동작하고, 3rd party들의 플랫폼과도 연동하여 전반적인 AI 생태계를 구성하고 있습니다. 그 중에서 이용자와 AI(인공지능) 간의 대화 품질 고도화를 위하여 솔트룩스 ADAMs.ai 플랫폼을 연동하였으며, 이를 통하여 광범위한 지식을 필요로 하는 생활형 심층 질의응답(QA) 서비스를 제공하고 있습니다.
< KT ‘기가지니’와 ADAMs.ai 간 연계 >
① 주요 내용
‘기가지니’는 이용자의 질문에 대한 답변을 찾아 전달하는 질의응답(QA) 서비스를 제공합니다. 광범위한 지식을 필요로 하는 생활정보, 일반상식, 전문지식 분야의 심층 질의응답(QA) 서비스를 위하여 솔트룩스의 ADAMs.ai가 연동되었습니다. ‘기가지니’를 통해 입력 받은 이용자의 질문이 ADAMs.ai 플랫폼에 전달되면, ADAMs.ai는 대규모 지식그래프 기반 심층 질의응답(QA) 기술을 통하여 전달받은 질문의 대한 답을 찾습니다. 이렇게 찾은 답변을 ‘기가지니’에 전달하여 사용자에게 원하는 답변을 제공합니다. 그 과정에서 질의응답에 필요한 새로운 지식을 지속적으로 추가 학습하여 질의응답의 품질을 고도화하고 있습니다.
② 적용 기술
앙상블 기술을 활용한 유연한 질의응답 KT ‘기가지니’는 ADAMs.ai에서 Open API를 통해 제공하는 심층 질의응답 (Deep QA) 서비스를 활용하여 생활정보, 일반상식, 전문지식 분야의 질문에 대한 답변을 구합니다. 심층 질의응답(Deep QA) 서비스는 입력된 질문에 대하여 지식그래프 기반 질의응답(KBQA), 정보 검색 기반 질의응답(IRQA), MRC 기반 질의응답(MRQA) 등이 앙상블 되어 질의 유형에 따라 최적의 풀이 방식을 채택하여 사용자에게 답변을 제공합니다.
지속적 QA 모니터링 및 지식 큐레이션 심층질의응답을 적용하는 생활정보, 일반상식, 전문지식 분야에 따라 지속적인 QA 모니터링을 지원하며, 지식 큐레이션을 통하여 매일 분야별 대규모의 신규 지식을 추가 구축합니다. 이렇게 구축된 신규 지식들은 플랫폼의 관리기능을 통하여 쉽게 질의응답에 활용 가능한 데이터로 변환됩니다.
③ 주요 성과
지식그래프로 구축된 약 8억 건의 일반지식을 대상으로 하는 복합추론에서 50만 단위지식/초의 속도를 제공하며, 이러한 복합추론과 일 데이터 수집량인 5백만 문서를 매일 지속 학습하는 강점을 통하여 생활정보, 일반상식, 전문지식 분야 질의응답 정답 확률 94% 수준을 제공합니다.
우리은행 AI(인공지능) 상담 시스템과 ADAMs.ai 연계
최근 금융 분야에서는 모바일을 비롯한 다양한 고객 서비스 채널이 확대되고 있고, 최신 인공지능 기반의 기술 트렌드에 대응하는 서비스 요구가 증가하고 있습니다. 우리은행에서도 대 고객, 대 직원 금융서비스의 패러다임 변화를 위하여 AI(인공지능) 상담 시스템 구축의 필요성이 대두되었습니다.
< 우리은행 AI(인공지능) 상담시스템 >
우리은행은 AI(인공지능) 기술을 이용해 고객과 실시간 상담이 가능한 챗봇 서비스 ‘위비봇’을 2017년 9월에 개시하였습니다. 24시간 실시간 금융 상담 서비스를 제공합니다. ‘위비봇’은 기존의 질문과 답변을 고르는 단순 선택형 방식이 아닌 질문자의 의도를 파악해 상담원처럼 고객과 대화하는 방식으로 답변을 제공하며, 금융정보 외에도 일반상식 정보도 제공합니다.
① 주요 내용
우리은행의 AI(인공지능) 상담시스템은 크게 데이터 영역, AI 플랫폼 영역, 그리고 서비스 영역으로 구분할 수 있으며, 특히, 날씨나 인물정보 등 일반상식 정보를 질의응답을 통해 제공하기 위하여 방대한 지식베이스 기반 플랫폼인 솔트룩스의 ADAMs.ai를 연동하였습니다. 금융 분야의 상담 서비스에 대한 지식은 데이터 영역에 자체 구축하여 상담 서비스에 활용하고 있으나, 단기간에 구축이 어려운 일반상식 정보에 대해서는 외부 오픈 플랫폼인 ADAMs.ai를 연동하여 서비스하고 있습니다.
② 적용 기술
지식그래프 기반 심층질의응답 우리은행 ‘위비봇’은 금융 분야 외의 일반상식에 대한 질문에 대하여 ADAMs.ai에서 Open API를 통해 제공하는 심층 질의응답(Deep QA) 서비스를 활용하여 구합니다. 심층 질의응답(Deep QA) 서비스는 아시아 최대 규모의 지식그래프를 기반으로 하는 복합추론을 통하여 일반 시사 상식에 대한 질의응답을 제공합니다.
새로운 지식에 대한 빠른 적용 심층질의응답을 적용하는 일반 시사 상식에 대한 새로운 지식을 생성, 학습, 추론하여 질의응답을 처리할 수 있도록 사전, 지식, 색인 등 정보를 관리할 수 있는 플랫폼을 제공하며, 쉽게 새로운 지식을 구축할 수 있고 해당하는 질의응답을 구현할 수 있습니다.
③ 주요 성과
우리은행 ‘위비봇’은 약 8억건의 일반지식에 대한 지식그래프를 내장한 ADAMs.ai를 연동하여, AI(인공지능) 챗봇을 통해 제공할 수 있는 서비스의 범위를 금융 분야 상담뿐만 아니라, 날씨, 인물정보 등 광범위한 일반상식 영역까지 크게 확대하였습니다.
Data Science Cloud Service
Data Science Cloud Service 현황
한국여성정책연구원 여성정책 소셜 빅데이터 수집 및 분석
데이터 관련 기술이 발전됨에 따라 과거 전통적인 조사 방법인 표본조사에서 빅데이터 기반 전수 조사로 연구의 흐름이 변화되고 있습니다. 이는 공공기관, 지차제, 기업 등 전 산업 분야로 확대되고 있으며 빅데이터 기반 행정 서비스 제공 및 증거 기반 정책 수립을 위한 다양한 정책이 추진되고 있습니다. 이에 여성정책연구 분야에서도 시시각각 변하는 사회 전반의 여론을 신속하게 분석함으로써 여성 정책수요를 파악하고 대응 방안을 마련하기 위한 기초 자료를 구축하고자 하였습니다.
< 여성정책연구원 분석프로세스 >
① 주요 내용
본 연구는 소셜 데이터를 수집 및 분석하여 소셜 미디어를 중심으로 전개되는 다양한 사회 현상과 젠더 이슈를 분석할 목적으로 추진되었습니다. 분석 방법으로는 솔트룩스 내부 솔루션인 단어 가중치 분석, 감성 분석, 동시 출현 단어 분석 등을 활용하였습니다. 시각화 차트를 활용한 분석 결과는 여성정책 추진에 필요한 기초자료를 제공하였다는 측면에서 중요한 연구 결과를 도출하였다는 평가를 받았습니다.
② 적용 기술
트랜드 분석 분석 대상에 대한 언급량을 월별/일별로 집계하여 언급량이 집중된 시기를 중심으로 사람들의 주요 관심사항이 무엇이고 어떤 담론이 생산, 확대, 축소되었는지 파악하였습니다.
단어 가중치 및 감성 분석 문서간/문서내 단어 빈도수를 이용하여 모든 문서에서 나타나는 흔한 단어들을 걸러 내고 중요 단어들을 추출하였습니다. 감성어휘 사전과 지도 기계학습을 이용하여 문장별로 감성을 분류하였습니다. 이를 기반으로 분석 대상 또는 단어에 대한 종합적인 감성을 파악하였습니다.
동시출현 단어 및 원문(VOC)분석 출현 빈도가 높은 중요 단어를 선별한 후, 해당 단어를 포함한 문장만 추출하였습니다. 단어 간 연관성을 파악하기 위해 주요 단어들이 함께 언급된 원문을 추출하였습니다. 추출된 원문을 검토하여 분석 대상에 대한 동향 및 연계 맥락을 파악하였습니다.
③ 주요 성과
특정 표본에 대한 제한적 이해가 아니라 대중 의견에 대한 종합적인 분석을 위해 본 연구에서는 페미니즘, 최저임 금 주제와 관련된 언론, 소셜미디어, 커뮤니티 데이터를 수집하였습니다. 또한, 수집된 데이터를 분석하여 여성정 책 추진에 필요한 기초자료를 마련하였습니다. 이는 과거 소수에 불과했던 미디어 연구를 확장한 연구 사례로써 향후 여성정책 수요를 발굴하고 대응 방안을 모색함에 빅데이터 활용을 촉진할 것으로 기대합니다.
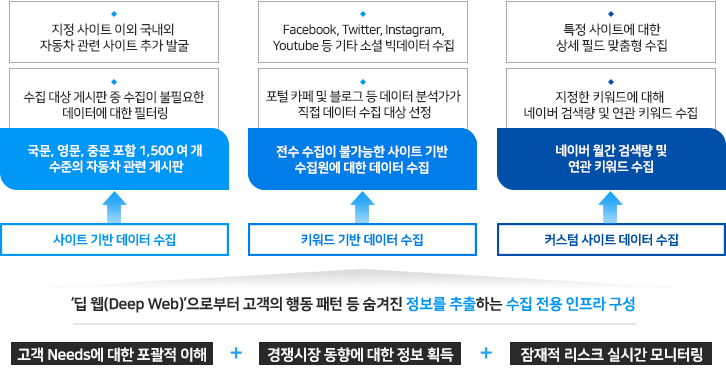
현대자동차 전세계 경쟁 차량 정보 수집
전세계 경쟁 차량 수집 서비스는 멀티 채널 다국어 외부 데이터를 주비한 후, 이를 활용한 적극적 마켓 센싱을 통해 고객 만족도 향상 및 시장 경쟁력 강화를 목표로 진행되었습니다. 이를 위해 수집된 전세계 경쟁 차량 정보로부터 고객 니즈에 대한 포괄적 이해, 경쟁 시장 동향에 대한 정보 획득 그리고, 잠재적 리스크에 대한 실시간 모니터링을 위해 대용량 데이터 수집 전용 인프라를 구성하였습니다. 데이터 수집 대상은 자동차 관련 전세계 모든 뉴스, 잡지, 카페, 커뮤니티 및 포럼 사이트뿐만 아니라 Facebook, Twitter, Instagram, YouTube 그리고, 고객 요청에 의한 커스텀 사이트로부터 데이터를 수집합니다. 수집된 데이터는 자동분류, 필터링, 정제 및 가공 과정을 거쳐 정규화 되어 고객이 바로 활용할 수 있는 데이터 형태로 구축하여 제공하였습니다.
< 현대자동차 데이터 수집 및 정제 서비스 >
① 주요 내용
본 사업은 멀티 채널의 외부 데이터를 수집한 후, 이를 활용한 적극적 마켓 센싱을 통해 고객 만족도 향상 및 시 장 경쟁력 강화를 목표로 진행되었습니다. 이를 위해 수집된 정보로부터 고객 니즈에 대한 포괄적 이해, 경쟁시장 동향에 대한 정보 획득, 잠재적 리스크에 대한 실시간 모니터링을 추출할 수 있는 데이터 수집전용 인프라를 구성하였습니다. 수집대상은 사이트의 자동차 관련 세부 게시판과 카페 사이트 및 키워드 기반 데이터, Facebook, Twitter, Instagram, Youtube, 기타 커스텀 사이트 데이터로서 수집된 데이터는 필터링 및 정규화 되어 고객이 바로 활용할 수 있는 형태로 제공하게 됩니다.
② 적용 기술
데이터 수집 고객 선정 약 1,500개의 수집 대상 사이틀르 검토하고 선별합니다. 큐레이션 센터에서 직접 수집 대상 사이트에 대한 메타데이터 조사 및 고객과 협의를 거처 데이터 필터링을 합니다. 검색결과 URL 추출 및 수집 데이터의 본문 내 URL 추출 후 빈도수 분석 및 큐레이터가 직접 자동차와 연관성이 높은 사이트를 추가 발굴합니다.
데이터 품질 자동화 데이터 필터링, 카페스키마 자동 감지, 기계학습 스팸 분류, 날짜 함수 정규화, 전송데이터 생성, 장애 감지 등의 기능을 수행합니다.
수집 현황 모니터링 대시보드 프로젝트의 수집 현황 실시간 모니터링, 각 프로젝트의 관리 현황 확인, 수집 위험도 상위 사이트 확인, 수집 데이터 추이 확인, 수집처 리스트 확인이 가능합니다.
③ 주요 성과
수집된 데이터를 통해 고객 Needs에 대한 포괄적 이해, 경쟁시장 동향에 대한 정보 획득, 잠재적 리스크 모니터링 진행, 고객의 행동 패턴 등 숨겨진 정보를 추출, 내부 분석에 바로 활용 가능한 고객 맞춤형 데이터를 제공하였습니다.
AIA생명 3645 싱글들의 보험상품 니즈 파악 및 그들을 대상으로 한 상품기획
보험상품의 개발에 있어 과거의 직관적 경험에 의존하던 방법에서 데이터 기반으로 상품을 기획하여 시장경쟁력을 높이는 것이 필요했습니다. 싱글족에 관련된 분석 대상 데이터를 확보하고, 확보된 정형/비정형 데이터를 융합분석 및 인지 분석을 통해 3545싱글들의 관심을 끌 수 있는 보험 상품을 개발하고자 합니다.
< AIA생명 3545싱글들의 보험상품 상품기획 >
① 주요 내용
본 사업은 "3545싱글들의 보험상품 니즈 파악 및 그들을 대상으로 한 상품기획" 목적을 위해 연령대별, 성별 소셜 빅데이터 수집 및 분석 서비스 사례입니다. 3545 싱글들의 타겟팅/이슈 및 가설 검증을 통해 인사이트를 도출했으며, AIA 생명 상품 전략 수립에 활용된 사례입니다.
② 적용 기술
가설 검증 시나리오 3545 싱글에게 관심을 끌 수 있는 보험 상품 개발을 위해 주제 키워드를 발굴하고 도출된 키워드를 그룹화하여 소비자들의 관심도와 평판을 분석합니다.
언급량 트렌드 분석 속성별 트랜드 비교를 통해 고객의 관심사항에 대한 동향과 경향성을 파악 및 상세 이슈사항까지 파악하고 검토합니다.
워드 클라우드와 연관어 분석 소비자들의 연관 이슈별 관심도 및 평판 분석을 하고, 연관 키워드들의 관계를 밝혀 통찰력을 제공합니다.
감성분석 속성별 상세 속성 키워드의 감성분석 결과와 버블차트 분석을 통해 언급량 대비 소비자들의 반응을 쉽게 파악합니다.
③ 주요 성과
멀티 채널의 외부 데이터를 활용한 적극적 마켓 센싱으로 고객 만족도 향상 및 시장 경쟁력을 강화할 수 있습니다. 대상의 변경만으로 손쉽게 맞춤형 상품을 개발할 수 있는 검증된 플랫폼을 확보할 수 있습니다.
PwC 컨설팅 실시간 기업 정보 및 모니터링 서비스
다양한 정보를 통해 기업의 현황 파악이 실시간으로 가능하게 함으로써 급변하는 기업의 사회적 변화에 대하여 신속히 대응하기 위한 기반이 필요하였습니다. 특히 방대한 량의 소셜 데이터와 SNS데이터의 수집과 이를 통한 분석 및 시각화는 특정 기업의 인사이트를 얻기 위해 필요한 수단이며 목표입니다.
< PwC 컨설팅 기업정보 및 모니터링 서비스 목적 >
① 주요 내용
150억건 이상의 소셜데이터를 기반으로 실시간 기업 정보 및 경쟁사 모니터링 서비스 제공합니다. 트랜드 분석, 키워드 비교 분석, 연관어 분석, 감성 분석, 사전관리등의 분석 및 기능을 제공하였으며 이를 바탕으로 기업에 대한 분석 및 모니터링을 함에 있어 중요한 결과를 제공했습니다.
② 적용 기술
소셜 데이터 검색 질의어를 포함하고 있는 문서를 뉴스, 블로그, 트위터의 각 검색 소스에서 추출하여 제공합니다. 전체 검색된 문서의 수와 중복을 제거한 문서의 수를 제공합니다.
트랜드 분석 주어진 질의어에 대해 뉴스, 블로그, 트위터에 등록되어 있는 문서의 기간별 통계를 제공합니다. 결과는 json 형태로 제공되며, 질의어에 해당하는 문서 통계 결과와 같은 기간의 전체 문서 통계 결과를 제공합니다.
연관 주제어 자동 분석 주어진 질의어에 대해 뉴스, 블로그, 트위터 데이터에서 연관 주제어들을 추출하고 출현 빈도를 기준으로 순위를 제공하며, 연결정보를 제공합니다. 입력된 기간에 대하여 단위 기간을 설정할 수 있습니다.
오늘의 토픽 분석 입력된 뉴스 카테고리에 대하여 N개의 오늘의 토픽을 추출하여 Ranking을 제공합니다.
③ 주요 성과
특정기업 및 경쟁사의 데이터를 수집, 저장, 분석, 표현의 전체 과정을 통합적으로 처리할 수 있습니다. 본 사업은 기업과 관련된 언론, 소셜미디어, 커뮤니티 데이터를 수집하였습니다. 기업에 대한 현황, 기술, 서비스형태 등 다양한 정보를 수집하고, 수집된 데이터의 분석을 통해 인사이트를 제공하며 맞춤형 정보로 활용할 수 있습니다.
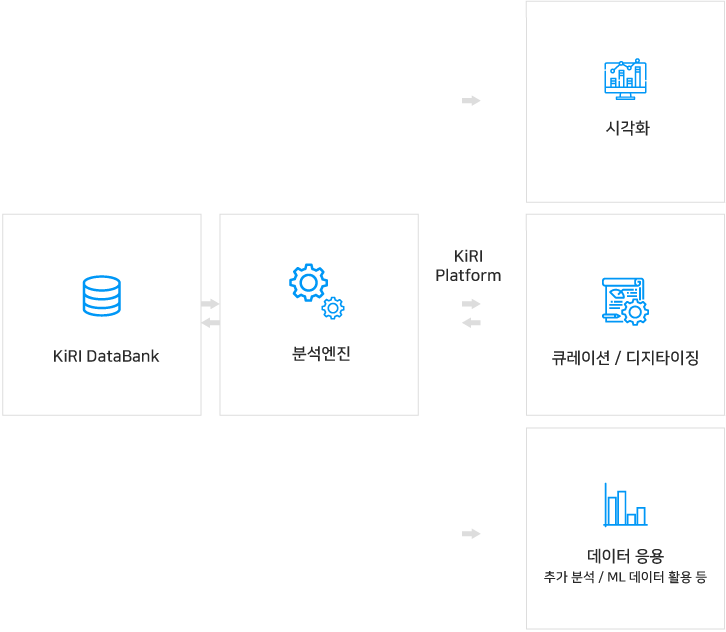
한국과학기술연구원(KIST) 데이터 기반 R&D 환경 구축 서비스
생산되는 디지털 데이터의 비중이 점차 증가하는 현실 속에서 연구기관에서 빅데이터를 활용한 연구지원 시스템 도입은 연구기관의 전체적 생산성을 높일 수 있습니다. 본 사업은 KIST가 지속적인 연구 개발에 대한 경쟁력을 가질 수 있도록 정형·비정형 데이터의 수집 및 관리체계를 확립하여, 연구원의 연구 생산성을 높일 수 있는 글로벌 스케일의 연구자료 분석 환경 구축을 하였습니다.
< 한국과학기술연구원 정보분석 플랫폼 >
① 주요 내용
연구기관에서 연구개발 생산성에 도움이 되기 위해서는, 내부의 연구정보가 실시간 공유되고, 외부(해외) 연구논문 정보와 연계되어 연구방향 설정에 도움을 주는 시스템을 구축하였습니다. 시스템은 촉매분야 관련 연구에 필요한 대내외 논문이나 특허 등 자료를 수집/정제 및 저장 관리하는 KiRI DataBank, 수집된 연구 자료에 대한 검색/분석할 수 있는 플랫폼인 KiRI Platform, 그리고 연구 데이터를 기록/관리를 위한 KiRI Note플랫폼으로 구성되어졌습니다.
② 적용 기술
연구 활동 기록 및 현황조회 연구노트 기능을 통해서 연구 활동을 효율적으로 관리할 수 있으며, 현재 진행중인 프로젝트 현황을 효율적으로 관리할 수 있습니다.
기본 논문 검색 분석 유사 논문/트랜드/연관어 분석 중심 키워드와 관련된 컨텐츠를 검색/분석하는 기능입니다. 기본 시계열 분석에서 부터, 트랜드 비교, 연관어 분석, 논문-저자 또는 물질-논문 네트워크 다이어그램까지 다양한 분석이 가능합니다.
논문 정보를 섬세하게 추출할 수 있는 큐레이션 툴 웹에서 크롤링한 논문의 기본정보 뿐 아니라 큐레이션 툴도 함께 제공합니다. 기본 초록 정보를 이용하여 자동으로 DB화 시켜주고, 큐레이션작업을 통해서 상세하고 전문적인 내용들을 구조화시켜 저장 관리합니다.
논문내의 분석 결과를 추출하는 디지타이징 논문에 수록된 그래프화 되어 있는 연구결과를 Data화 할 수 있는 디지타이징 툴을 제공합니다. 추출할 이미지 선택 및 축, 대상 등을 설정하면 그래프 이미지를 디지털 정보화 할 수 있으며 결과는 논문별 저장소에 저장 관리되어집니다.
③ 주요 성과
실험정보의 공유를 통하여 연구생산성 및 커뮤니케이션의 질적 향상을 통한 연구지원이 가능하게 되었으며, 대내외 연구 논문 및 특허정보를 DB화 함으로 촉매 분야별 최신정보 센싱 및 논문 활용을 향상시켰습니다. 각종 실험을 통하여 발생하는 실험노트를 데이터화하고 데이터마이닝, 인공지능(AI)등 데이터사이언스에 용용 합니다.
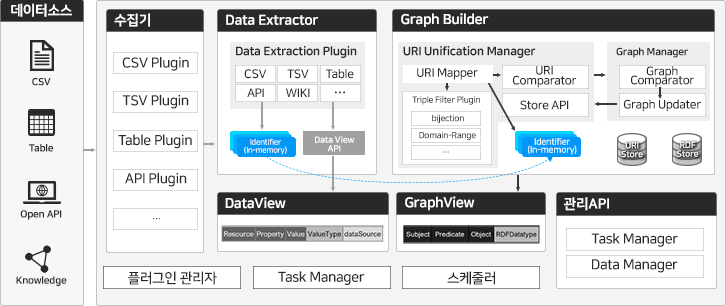
(304100) 솔트룩스 - (3) 그래프 DB ( Graph DB Suite 기술소개 )
saltlux
동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
그래프 DB (Graph DB Suite)
그래프 데이터베이스 인식 및 기술 패러다임 변화
2018년 기준으로 전세계 GraphDB 시장 중 아시아의 비중은 18.2%로 미국이나 유럽보다 시장 규모는 작지만, 년 상승률은 28.3%로 가장 큰 것으로 나타나고 있습니다. 따라서 아시아 IT 인프라 발전과 중·소 규모의 GraphDB 기업들의 가치가 다른 대륙 기업들의 기대치보다 높게 나타나고 있습니다.
< 그래프 데이터베이스의 시장 점유율 및 상승율(2018년) >
시장 변화에 따른 제품 혁신의 통찰력
현재 GraphDB 시장은 기업들의 시장 욕구를 토대로 기술력이 발전하면서 점차적으로 확대되어 2023년에는 전세계적으로 2.4 billions 규모로 커질 것으로 기대하고 있습니다. 이에 따라 솔트룩스는 내제된 솔루션을 정립하고 더 나아가 맞춤형 솔루션을 체계화하여 시장 대응력을 강화하였습니다.
< 그래프 데이터베이스 마켓 성장 및 기술변환에 따른 시장 성장 >
소개
GraphDB Suite는 다양하고 방대하게 쏟아지고 있는 빅데이터를 효율적으로 활용 및 관리하기 위하여 데이터 간의 상관관계를 지식그래프 구조로 자동 변환·생성하여 저장뿐만 아니라 분석에 바로 활용할 수 있는 분석 기능을 내장합니다. 또한, 국내 최고의 지식그래프데이터 생성에서부터 관리, 지능형 분석(예측·추론)이 가능한 최고의 제품으로 비즈니스 환경에 따라 Add-on 패키지를 선택적으로 사용하여 데이터 통합, 리스크 관리, 콘텐츠 추천, 데이터 공개, 대용량 추론 기능을 제공합니다.
< GraphDB Suite 개념도 >
GraphDB Suite은 멀티 데이터 모델 통합 서비스, 데이터 예측/진단 서비스, 링크드 오픈 데이터 서비스, 대용량 지식그래프 구축 서비스를 구축할 수 있는 환경을 제공하고 있습니다.
< GraphDB Suite 구성도 >
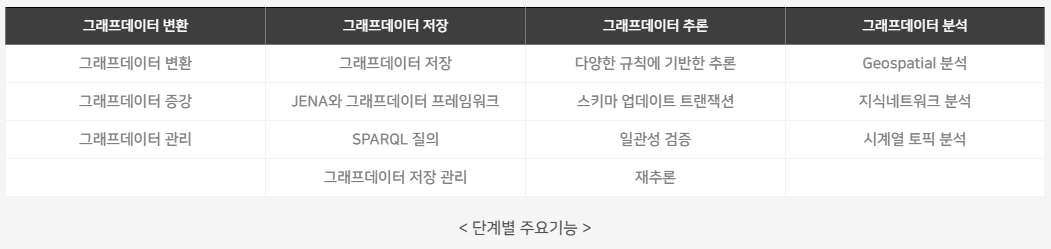
주요 기능
GraphDB Suite는 데이터를 그래프데이터로 변환하기 위한 변환기능, 그래프데이터 저장소, 그래프데이터 기반 지오데이터 분석과 지식 네트워크 분석, 그래프데이터 개방 기능, 시각화와 운영관리에 이르는 그래프데이터의 생명주기에 해당하는 모든 기능을 제공하고 있습니다.
주요 특성
GraphDB Suite은 비즈니스 환경에 따라 최적화된 솔루션을 선택하여 적용해야 합니다. 비즈니스 환경은 기업이나 기관이 보유한 데이터의 유입 속도, 데이터의 볼륨에 따라 크게 좌우되며, 또한 서비스의 종류에 따라 지식베이스 구축의 기술 난이도도 상이하게 달라지게 됩니다. GraphDB Suite는 고객의 니즈를 충족시키고 최적화된 서비스를 제공할 수 있게 함으로써 그래프 데이터 기반의 새로운 시장창출과 고객발굴, 고객의 경제적 가치를 높이는 최적의 솔루션입니다.
주요 경쟁력
GraphDB Suite 제품은 지식그래프 기반 인공지능기반 서비스(고객상담 서비스, 인공지능 스피커의 질의응답 서비스 등)와 결합된 국내 최초 제품입니다. GraphDB Suite은 그래프 데이터변환부터 통합, 저장, 추론/질의, 분석, 관리, 활용에 필요한 모든 기능을 하나의 프레임워크에서 제공하는 플랫폼입니다.
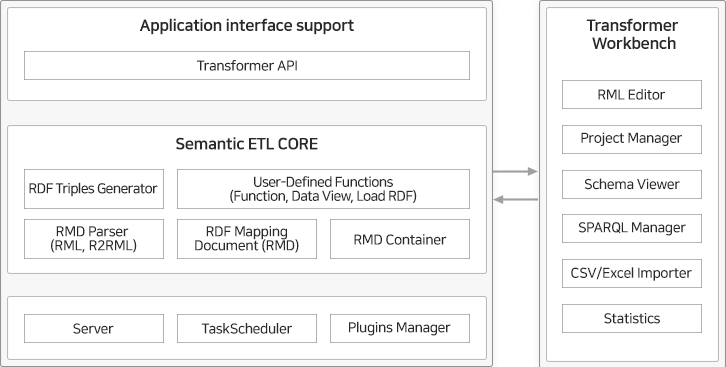
그래프데이터변환 엔진
구조화 데이터에는 RDBMS, 엑셀, CSV, TSV, RDF 등 데이터가 일정한 구조를 가지는 것을 말하며, 비구조화 데이터는 웹문서, 매뉴얼 등의 문서의 구조를 가지는 데이터를 말하며, 이렇게 내/외부 산재되어 있는 다양한 대용량의 데이터들 간의 아주 복잡한 관계를 더 쉽고 빠르게 파악할 수 있도록 Graph DB에 저장하기 위하여 그래프데이터로 변환하여 통합 처리하는 프로세스에서 시작합니다.
데이터를 변환하는 방법에는 데이터 소스의 구조와 지식그래프 데이터 모델을 매핑하거나 비구조화된 문서에서 지식그래프 모델에 해당되는 특정 리소스의 속성, 값 형태로 데이터를 추출하여 그래프 데이터로 변환할 수 있습니다. 또한, W3C의 RDF Direct Mapping 기술을 통해서 RDB와 RDF를 직접 연결하고 통합할 수 있습니다.
솔트룩스의 데이터변환엔진은 변환 및 통합을 위한 매핑 언어인 RML(Rule Mapping Language)과 W3C의 R2RML을 지원하고 있으며, RDB 뿐만 아니라 다양한 데이터 소스를 지원하고 매핑 과정에서 데이터에 대한 정제 및 필터링을 지원함으로써 양질의 그래프데이터 확보 및 처리에 적합한 엔진입니다.
< 그래프데이터변환 엔진 – 데이터변환 개념도 >
소개
그래프데이터변환 엔진은 데이터 소스(DBMS, CSV, RDF 등)와 지식그래프 모델간 매핑을 통해 지식그래프에 해당되는 데이터를 생성하기 위한 엔진입니다. W3C의 R2RML언어 지원뿐만 아니라 자체 데이터변환 규칙인 RML언어 제공을 통해 RDB와 같은 구조화된 형태를 가지는 모든 데이터를 대상으로 변환하는 기능을 제공하며, 사용자 데이터를 가상의 데이터 뷰(Data View)로 전환하고 처리하기 위한 기능을 제공하고 있습니다. 사용자는 그래프데이터변환엔진을 통해 데이터변환 업무를 쉽고 빠르게 수행할 수 있습니다.
< 그래프데이터변환 엔진 – 기능 구성도 >
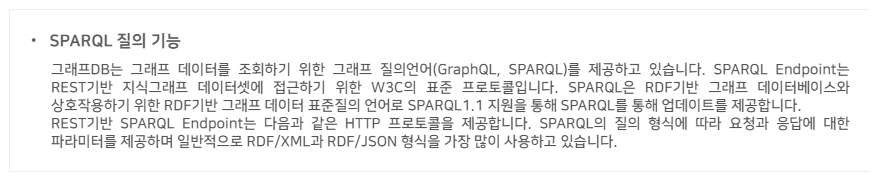
데이터변환 엔진의 관리 기능은 데이터 매핑 및 변환 뿐만 아니라 데이터 소스 뷰어, 데이터 모델(스키마) 뷰어, SPARQL 뷰어 및 테스트, CSV/Excel 파일 뷰어, RML 편집기 및 테스트, 변환 통계기능 등 사용자가 데이터변환 처리(데이터 전처리, 변환, 데이터 후처리)에 있어 유용한 기능을 제공하고 있습니다.
< 그래프데이터 변환 절차 >
데이터변환 절차는 데이터 소스 선정, 데이터 소스에 해당되는 데이터 뷰 생성, 그래프 맵 정의, 데이터 뷰와 그래프 맵 바인딩, 그래프데이터 생성의 절차로 진행합니다. 그래프 맵은 그래프 모델에 해당되는 인스턴스를 정의하며 특정 리소스의 속성값을 생성할 때 값에 대한 필터링/정제가 필요할 경우는 함수를 이용하여 처리합니다.
< 대용량 비졍형데이터 지식 추출 절차 및 도구 >
주요 특징
그래프데이터변환 엔진은 대용량 데이터에 대한 변환뿐만 아니라 다양한 데이터 소스를 지원하는 가상의 데이터 뷰를 제공, 데이터변환 시 데이터에 대한 정제 및 필터링 제공 등 사용자가 정의한 데이터 뷰와 필터링 함수를 직접 정의하고 엔진에 적용할 수 있습니다. 그래프데이터변환 엔진의 가장 큰 장점은 사용자가 데이터 뷰(Data View)를 만들거나 사용자 함수(필터링, 정제 등)을 플러그인으로 만들 수 있으며, 이들은 모두 URI주소를 가지고 있어 다른 프로젝트(작업)에서 동일한 함수가 URI를 통해서 구분하여 사용할 수 있는 장점이 있습니다. 또한, 형상관리 서버(SVN, CVS, Git 등)와의 연동을 통해 작업중인 프로젝트 별 형상을 관리할 수 있습니다. 다음과 같은 주요 특징들을 가지고 있습니다.
주요 기능 및 사양
Graph DB Suite에 정형과 비정형 데이터에 대한 그래프데이터 생성을 담당하는 그래프데이터변환 엔진은 데이터변환 핵심기능과 손쉬운 변환 작업을 지원하는 관리도구로 구성되어 있습니다. 정형화된 데이터의 경우 스키마 매핑을 통해 데이터를 추출/변환할 수 있으며, 비정형화 데이터의 경우는 KENT의 데이터 추출 기능을 결합하여 데이터 모델에 필요한 속성의 값을 추출하고 변환할 수 있습니다.
다양한 포맷을 지원하는 데이터변환 기능
Graph DB Suite의 데이터변환 기능은 그래프데이터를 생성하기 위한 절차와 방법을 제공하고 있으며, 변환 전 결과에 대한 사전 테스트와 변환 결과를 Graph DB에 직접 저장할 수 있는 기능을 제공하고 있습니다. 핵심 기능들은 대부분 플러그인 형태로 구성되어 사용자 환경에 맞게 기능을 최적화할 수 있는 있습니다.
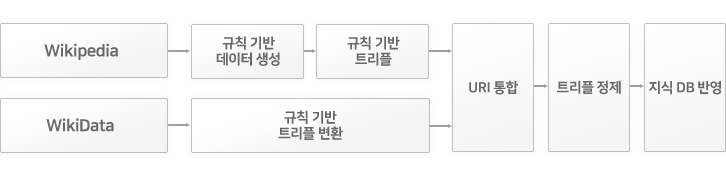
초 대용량 그래프 데이터변환과 증강 기능
그래프데이터변환 엔진은 위키피디아, 위키데이터 등 내/외부에 존재하는 큰 데이터셋에 대한 지식변환과 지식그래프 데이터에 대한 증강 및 오류보정 등 복잡한 데이터변환 프로세스와 방법을 제공합니다.
데이터 수집, 추출, 리소스 통합 및 보정, 그래프 데이터 생성 등의 기능을 제공하고 있으며, 플러그인 방식으로 기능을 추가하거나 최적화할 수 있습니다. 또한, 변환과정을 관리하고 통제하기 위한 관리 API를 제공하고 있습니다.
데이터변환 엔진 관리 기능
변환 엔진 관리도구에는 데이터변환 규칙 편집 및 실행, 데이터 소스, 사용자 함수, SPARQL, 리소스 뷰어 등의 기능이 있으며 사용자는 해당 기능을 사용하여 변환 규칙을 쉽고 빠르게 작성할 수 있습니다. 변환 엔진의 모든 함수는 네임스페이스에 기반하고 있어 중복되는 함수이름도 네임스페이스를 통해 구분하고 사용할 수 있습니다. 관리도구의 규칙 편집기는 변수, 함수 등에 대한 자동완성을 제공하고 있으며, 사용자의 데이터 모델을 가져오기 하면 자동으로 클래스, 속성을 편집기에서 자동완성 항목에 포함시켜 사용자가 클래스/속성을 쉽게 참조하여 변환규칙을 생성하는 데 사용할 수 있습니다.
주요 엔진 화면
그래프데이터저장 엔진
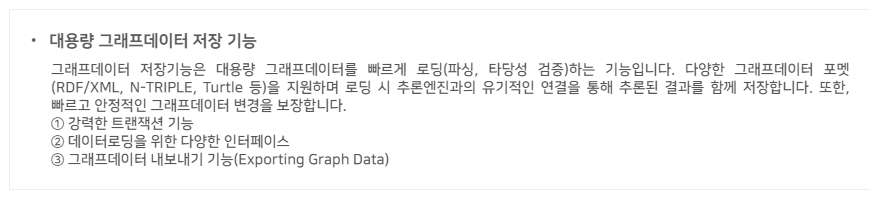
Graph DB Suite에서 100억 트리플 이상의 초 대용량 그래프데이터를 저장하고 활용할 수 있는 그래프데이터 저장 엔진을 제공하고 있습니다. 그래프데이터 저장 엔진은 개념간 상·하위 추론과 관계추론 및 검증을 위한 3.3.2.3의 공리(Axiom)를 제공하고 있으며, 이를 통해 새로운 사실을 생성하고 저장할 수 있습니다.
Graph DB Suite은 W3C의 그래프 모델인 RDFS, OWL과 OWL2을 지원하고 있으며, 아파치 TinkerPop과 Gremlin 서버 연동을 통해 (Labeled) Property Graph 모델을 저장하고 질의할 수 있습니다. 사용자는 2가지의 데이터모델을 목적에 따라 선택적으로 사용이 가능합니다.
그래프데이터 저장 엔진은 데이터를 조회, 수정/삭제하기 위한 질의 언어를 제공합니다. W3C의 SPARQL과 GraphQL를 제공하고 있으며, 데이터 개방, 공유, 분석 등을 위해서 Rest기반 API를 통해 쉽고 빠르게 접근할 수 있습니다.
소개
그래프데이터 저장 엔진은 기본적으로 RDF기반 그래프데이터를 저장하는 저장소와 Property Graph를 저장하는 저장소 기능을 제공하며, 아파치 TinkerPop과 Gremlin 서버 연계를 통해 Property Graph를 저장하고 분석할 수 있는 기능을 제공하고 있습니다. RDF기반 그래프데이터는 트리플(triple)로 데이터가 표현되고, Property Graph는 Vertex, Edge로 표현되고 Vertex와 Edge은 속성(property)를 가질 수 있습니다.
주요 특징
주요 기능 및 사양
주요 엔진 화면
그래프데이터추론 엔진
Graph DB Suite에서 강력한 지식표현과 추론, 그래프 데이터의 저장은 추론을 통해 변환된 데이터로부터 새로운 사실을 발견하고 저장할 수 있습니다. 특히 데이터 모델에서 개념 간의 상·하위 추론과 개념 간의 관계추론을 위한 스키마 공리와 인스턴스 공리를 제공하고 있습니다.
Graph DB Suite은 W3C의 그래프 모델인 RDFS, OWL1, OWL2을 지원하고 있으며, (Labeled) Property Graph 모델을 저장하고 질의할 수 있습니다. 사용자는 2가지의 데이터모델을 목적에 따라 선택적으로 사용이 가능합니다.
소개
그래프데이터추론 엔진은 규칙기반 추론을 위한 2가지 리즈닝 전략(전방연쇄 (forward-chaining)과 후방연쇄(backward-chaining))을 제공하고 있습니다. 기본적으로 전방연쇄에 기반한 추론전략을 제공하며 필요시 후방연쇄 추론엔진을 사용할 수 있습니다. 전방연쇄에 기반한 추론의 장단점은 데이터가 저장소에 트랜잭션 후에 유추된 사실을 확장하기 때문에 새로운 사실을 업로드, 저장, 추가, 삭제 시 상대적으로 느려질 수 있습니다. 그래프데이터추론 엔진에서 추론은 데이터 입력 시점부터 시작됩니다. 하지만, 전방연쇄 추론기법의 장점은 모든 데이터에 대한 추론결과를 미리 만들어 저장함으로써 질의와 검색에 상당히 빠른 성능을 제공합니다. 일반적으로 후방연쇄 추론기법은 질의나 검색 시 추론이 발생하며 이로 인해 복잡한 연역추론이나 적합성 검사나 다른 추론이 발생할 가능성이 높아 성능에 영향을 미칠 수 있습니다.
주요 특징
그래프데이터 저장과 분석은 강력한 지식표현과 데이터 멀티 모델 지원을 통한 데이터 통합, 그래프데이터에 대한 다양한 분석기능을 제공합니다. 그래프데이터 저장과 분석의 주요 특징은 다음과 같습니다.
주요 기능 및 사양
주요 엔진 화면
그래프데이터분석 엔진
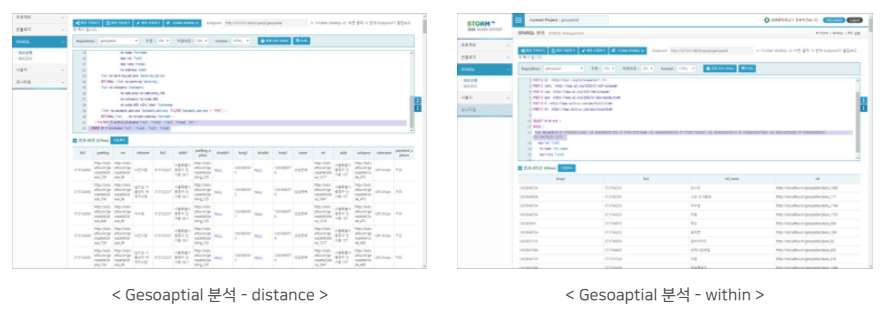
Graph DB Suite의 그래프데이터분석 엔진은 그래프데이터 기반 공간정보분석, 네트워크분석, 토픽분석을 제공합니다.
소개
그래프데이터분석 엔진은 외부정보(소셜미디어, 이메일, 지식관리 시스템 등)에 대한 지식그래프 생성기, 지식네트워크 분석을 위한 그래프 인덱스 생성기, 사용자별, 시간대별, 토픽별 지식네트워크 분석기, 네트워크 상에 유통되는 컨텐츠에 토픽(핵심어)분석을 위한 토픽네트워크 분석기, 시간대별 관심 토픽에 대한 경향성 분석기, 지식 검색기로 구성되어 있습니다.
주요 특징
그래프데이터분석 엔진의 특징은 실시간으로 수집/변경되는 지식에 대한 실시간 반영과 분석을 제공하며, 특히 수집된 데이터를 지식으로 변환하는 그래프데이터변환 엔진을 포함하고 있습니다. 또한, 그래프데이터분석에 필요한 데이터의 저장과 분석 색인 및 알고리즘을 제공하고 있으며, 분석 서비스 관점에 따라 사용자가 적절한 분석 알고리즘을 선택하여 결과를 얻을 수 있습니다. 모든 결과는 테이블 형태뿐만 아니라 RDF포멧(RDF/XML, Turtle, N-Triple, RDF/JSON 등)을 지원하고 있습니다.
주요 기능 및 사양
주요 엔진 화면
그래프 DB (Graph DB Suite) 적용사례
컴플라이언스 시스템 구축
지능형 범죄예방 협업 체계 개발 – 대검찰청
“국민안전”이 정부의 주요 국정전략임에도 불구하고 일시적인 인력·예산 투자 (치안인력 증원, CCTV 설치, 캠페인 강화 등) 및 기관별 범죄예방활동만으로는 지속적이고 장기적인 범죄예방 어려움을 겪고 있습니다. 발생 범죄를 세부적으로 분석하고 관계기관간 정보를 공유, 협업하여 국민에게 실효성 있는 범죄예방을 위한 과학적인 범죄분석체계 확립을 통하여 선제적 예방 중심의 형사사법체계 강화할 수 있는 지능적 시스템이 필요하며, 범죄정보, 행정사회정보를 과학적으로 분석하고, 관계기관이 공유하여 교육, 수사, 범죄자 사후 관리 및 피해자·가해자의 정상적인 사회 복귀 실현을 위한 국민정부지방간 긴밀한 공동의 협업 시스템 필요한 상황입니다. 이러한 두가지 관점의 큰 문제점을 해결하기 위하여 과학적인 범죄분석 기반 시스템 구축과 범죄 그래프데이터 기반의 지능형 범죄분석체계 확립 및 관계기관간 범죄예방 협업체계 구성 기반을 마련하였습니다.
< 지능형 범죄예방 분석시스템 >
① 사업의 내용
과학적인 범죄분석 기반 시스템 구축
5대 강력범죄 (살인, 성폭행, 강도, 방화, 폭행상해치사)에 대한 정형/비정형 데이터 융합 분석 인프라 구축
약 800여종의 반정형 비정형 문서 텍스트 분석
범죄분석을 지원하는 다양한 시나리오 설계
범인의 음성, 영상, 사진 등 범죄 증거자료 분석
기술 방법론 연구 (외부 POC 수행)
지능형 범죄분석 지식 기반 구축
심층 범죄 분석을 위한 기반 자료 구축
심층 범죄 분석용 컨셉사전 및 범죄 분류체계 구축
심층 범죄 분석의 자동화를 위한 기계학습 데이터 및 지식표현 체계 구축
관계기관간 범죄예방 협업체계 기반마련
관계기관 범죄예방 수립 시 요구되는 정보 식별
관계기관 연계 기반 방안 마련
② 적용 기술 및 솔루션
Graph DB Suite 제품 적용 범죄 분석에 필요한 Concept사전, Taxonomy, 범죄유형정보, 분석모델을 기반으로 범죄사전 정보에 대한 그래프데이터 생성 및 저장, 추론, 분석을 위하여 Graph DB Suite 제품 적용
Big Data Suite 제품 적용 Big Data Suite 제품 중 지능형 시맨틱 검색 서비스를 위하여 빅데이터 저장/검색엔진(DISCOVERY)과 수집된 비정형 데이터 분석을 위하여 비정형 빅데이터 분석 엔진(TMS), 인지 분석 엔진(CAS)를 적용
Apach SPARK, STORM, KAFKA 등 적용 OpenSource Apach SPARK, STORM, KAFKA 등을 지능형 범죄예방 분석시스템에 반영하여 Graph DB Suite 제품, Big Data Suite 제품과 연계를 통한 최적의 품질을 보장하는 지능형 분석 플랫폼 구성
③ 제품 선정 당위성
온톨로지 기반 실시간 분석 및 객체간 관계 시각화 필요
과학수사, 형사정책, 범죄예방 관련 분석 결과에 대한 시각화 필요
한국 범죄에 특화된 범죄 텍사노미 구성 필요
그래프데이터 통합 플랫폼 구축
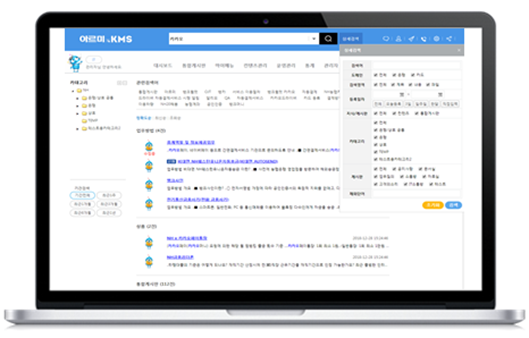
지능형 KMS 시스템 구축 – 농협은행
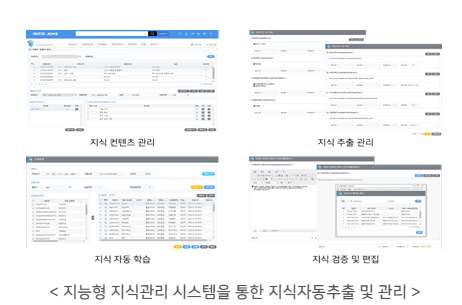
농협은행 고객행복센터 및 전 영업점에서 고객상담에 필요한 업무 지식을 관리하고 공유하는 지식관리 시스템을 개선하였습니다. 지식 생성, 관리, 검색 등의 사용 편의성을 높이고, 지식 컨텐츠 생성 시, 업무 분야와 속성에 따라 구체적으로 관리되도록 하여 Knowledge-Graph 기반의 지식베이스로 변환 저장합니다. 이는 자연어 컨텐츠를 시스템이 이해 가능한 형태(machine readable)의 지식 데이터로 변환하는 것이며, 이 과정에서 인공지능 기반 지식 자동 추출도 적용하였습니다.
< 지능형 KMS 시스템 UI/UX >
① 사업의 내용
기존의 지식관리 시스템은 고객 상담을 위해 필요한 업무 지식을 생산, 저장 관리하는 시스템으로, 은행 상담사 또는 영업점 직원들 간 지식을 공유하기 위한 목적으로 사용되고 있습니다. 하지만, 은행 고객들의 다양한 디지털 채널 사용이 많아 짐에 따라, 인공지능 기반의 서비스 요구가 지속적 증가하고 있고, 인공지능 서비스를 위해서는 별도의 AI 기반 지식 데이터구축 관리가 필요합니다. 기존 지식 컨텐츠와 AI 기반 지식 데이터는 형태와 구조가 서로 상이하여 개별적으로 관리하기에는 동일한 정보를 유지하기 어렵고, 중복된 지식 생성, 관리 및 활용으로 여러 측면에서 사용자에게 불편함을 주고 있는 상태입니다. 농협 은행에서는 10년 이상 사용한 노후화된 지식관리 시스템을 최신 인공지능 기술 트렌드에 부합하는 지능형 지식관리 시스템으로 개편하여, 직원들 간 상담 지식정보 관리 및 공유의 편의성을 높이는 것은 물론, 인공지능 기반 서비스에 활용 가능한 지식 데이터를 동시에 생성 관리함으로써, 지식 컨텐츠의 관리 효율성과 활용성을 높이는 것을 목표로 합니다.
< 지능형 KMS 시스템 개요 >
② 적용 기술 및 솔루션
지식그래프 기반의 지식 데이터 생성 관리 지능형 지식관리 시스템에서는 지식 컨텐츠를 생성할 뿐만 아니라, 지식그래프(Knowledge-graph) 구조에 따라 시스템이 이해 가능한 형태(machine readable)의 지식 데이터를 생성하고 관리할 수 있습니다. 이러한 지식 베이스는 다양한 인공지능 기반 서비스에 활용될 수 있습니다.
비정형 텍스트로부터 지식 자동 추출 지식 컨텐츠는 사용자들이 쉽게 이해 가능한 형태(TEXT 또는 HTML)의 문장 또는 단락으로 작성되어 있습니다. KENT(Knowledge Extraction from Natural Language Text) 기술은 딥러닝으로 학습된 모델을 기반으로 이러한 비정형 텍스트로부터 지식 데이터를 자동으로 추출하고 변환합니다.
③ 제품 선정 당위성
국내 최고의 품질 및 성능을 보유한 지식그래프를 저장하기 위한 저장소 선정
비정형 문서의 지식 추출을 위한 기계학습기반의 지식 추출 솔루션 선정
④ 주요 성과
농협은행/농협카드 지능형 지식관리 시스템과 질의응답 시스템 연계 농협은행과 농협카드의 지능형 지식관리 시스템을 각각 구축하여 별도의 컨텐츠를 관리하고 서로 지식 공유가 가능하도록 연계하였습니다. 또한, 콜센터 상담 어드바이저로 서비스되는 인공지능 질의응답 시스템과 연계하여 지능형 지식관리 시스템을 통해 관리는 지식데이터가 직원들과 시스템에 동시에 서비스되는 환경을 구축하였습니다.
지식 자동 추출 기술 상용화 지식 자동 추출은 아직까지 많은 연구 개발의 노력이 필요한 기술 분야입니다. 품질 향상을 위해 언어처리와 기계학습을 포함한 다양한 방안들을 연구하였고, 농협은행의 컨텐츠로부터 필요한 지식을 추출하는 범위에서는 만족할 만한 수준의 성과를 보였습니다. 지식 자동 추출을 실제 서비스에 적용한 성공 사례로 볼 수 있습니다.
안전 먹거리 질의응답 시스템 - 한국식품안전관리인증원
① 사업의 내용
국민생활과 밀접한 HACCP 인증 안심먹거리 기반으로 제품의 원재료, 영양성분 데이터를 활용하여 지식베이스를 구축하고, 더 나아가 테마기반의 개인화된 안심먹거리 추천 서비스를 대국민에게 제공할 수 있는 “HACCP 지능정보서비스를 위한 인공지능 기반 고객 맞춤형 지식 상담 서비스 개발”을 목표로 합니다.
< 안전먹거리 질의응답 시스템 목표 구성도 >
< 안전먹거리 질의응답 UI/UX >
② 적용 기술 및 솔루션
QA Manager: 사용자 질의처리와 인터페이스 제공(Open API)
KBQA: FBQA & TBQA &Plugin
FBQA: 팩트(facts)기반 질의처리
TBQA: 템플릿 기반 질의처리 기능, 복잡하거나 복합적인 질의처리
Plugin: 날씨, 뉴스, 세계시간 등 실시간 변경되는 데이터에 대한 질의처리
IRQA: 텍스트 분석을 통해 질문과 유사한 질문을 찾아 랭킹 된 답변을 제공
KB(Ontology): 질의처리에 필요한 오픈 도메인 지식베이스(OWL ontology: RDF + Axioms)
NLU: 자연어 질의 분석 및 패턴인식
NLG: 질의처리 결과에 대한 자연어 질의 생성
분석사전관리: 질의분석 및 질의패턴에 필요한 자원관리
QA관리: KB관리, 질의테스트, QA평가, KBQA분석사전관리
③ 제품 선정 당위성
지식그래프를 저장하기 위한 저장소 사용
비정형 문서의 지식 추출을 위한 기계학습 솔루션 사용
④ 주요 성과
사용자들에게 테마기반의 맞춤형 식품정보를 제공 가능
정보취약계층에 대한 접근성을 강화하고 안심먹거리에 대한 알 권리 향상
지능형 안심먹거리 서비스의 정보 획득 시간 단축 비용절감 효과
지능형 HACCP 상담서비스의 민원상담 및 기술지원방면의 비용절감 효과 기대
링크드 데이터(LOD) 서비스 구축
맞춤형 IP-Biz 정보공유 플랫폼 개발 – 특허청
① 사업의 내용
특허청이 보유한 지식재산권 정보를 중심으로 타 정부부처 및 공공기관이 보유 중인 다양한 비즈니스 정보를 연계하여 활용할 수 있는 정보채널을 구축하고, 중소기업 및 창업기업 등 기업 종사자들이 빠르고 편리하게 정보를 획득할 수 있는 사용자 관점의 편의 기능을 제공하였습니다.
동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
빅데이터 Bigdata Suite
데이터 인식 및 기술 패러다임의 변화
2010년 전후로 시작된 데이터 급증은 대규모 데이터의 저장과 처리를 위한 새로운 기술을 요구하고 있으며, 이 가운데에서 빅데이터라는 용어가 등장했습니다. 빅데이터는 거대한 데이터의 집합 또는 이를 저장·전송·처리할 수 있는 기술을 의미합니다. 4차 산업혁명 시대에 접어들면서 데이터가 모든 산업의 발전과 새로운 가치 창출의 촉매 역할을 하는 ‘데이터 경제(Data Economy)’로 패러다임 전환 중이며, 선진국은 국가 경제의 지속성장 및 일자리 창출을 위해 AI와 빅데이터 접목을 통한 주력산업의 재도약과 혁신성장을 도모하고 있습니다.
최근 데이터 혁신을 주도하는 새로운 기술로 AI(인공지능) 기술이 주목을 받으면서, 스스로 데이터를 전처리하고 학습용 데이터로부터 문제해결 로직을 만들어내는 등 데이터사이언티스트의 역할을 대체하고 있습니다. AI 기술이 빠르게 진화함에 따라 데이터와 기술이 융합해 지능화를 촉진하며 새로운 패러다임 변곡점이 발생하고 경제시스템과 사회구조 변화 유발을 시킴으로써 새로운 지능정보사회의 뉴 패러다임 구축되고 있습니다.
< 지능정보사회의 패러다임 변화 >
시장 변화에 따른 제품 혁신의 통찰력
솔트룩스는 기술발전의 변화를 통찰력 있는 사전예측을 통하여 창립이래 체계적인 기술 개발 로드맵을 수립하여 자연언어처리와 시맨틱, 추론을 포함한 인공지능 원천기술을 확보해 왔으며 시맨틱 검색과 텍스트 마이닝을 넘어 빅데이터 기반의 기계학습, 심층학습과 지식그래프 기반의 추론을 융합한 탁월한 성능과 기능의 스마트 데이터 제품과 플랫폼을 만들어 왔습니다.
전통적 데이터 분석뿐만 아니라 지능정보사회 즉 데이터 경제를 이끌어 갈 데이터 생태계의 가치사슬(데이터의 수집·저장·유통·활용)을 기반으로 공급중개-수요 시장을 통해 경제적 가치(신제품·서비스, 일자리 등) 창출할 수 있는 데이터로부터 스스로 학습하고 지식을 축적하며 분석/추론 및 심층학습을 통하여 전문가 수준의 문제 해결 및 데이터 주도적 의사결정을 지원할 수 있는 Bigdata Suite을 출시하였습니다.
Bigdata Suite는 4차 산업혁명 시대의 데이터 경제 및 데이터 사이언스에 이바지할 수 있는 End-to-End One stop 지능형 실시간 빅데이터분석 통합 플랫폼으로 체계적인 개발 관리 프로세스를 통하여 끊임없는 제품 성장을 이루어 가고 있으며, 제품 품질 확보를 및 신뢰성 있는 검증을 통하여 국내 및 국외 다양한 공공기관, 기업 및 연구기관 등 구축 사업에 납품실적을 다수 보유 하고 있으며 제품에 대한 품질 검증 및 철저한 제품관리체계를 통하여 신뢰성을 확보하고 있습니다.
솔트룩스 Bigdata Suite은 다음과 같은 6개의 엔진을 제공합니다.
소개
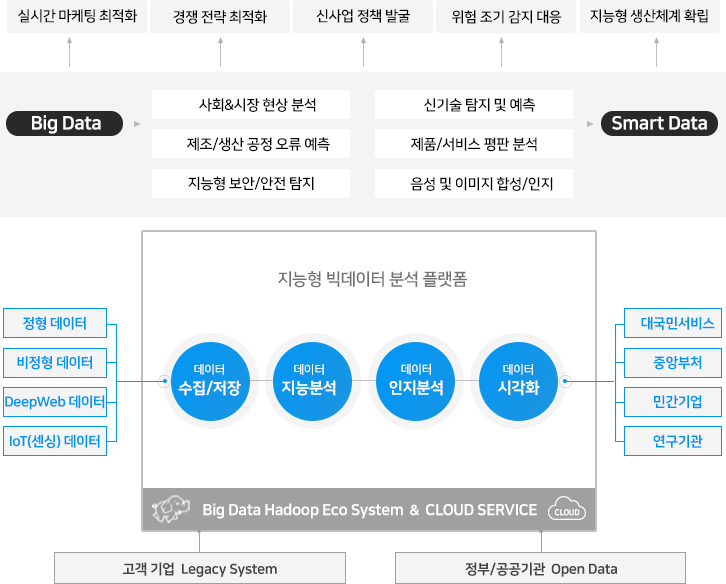
Bigdata Suite는 정형 빅데이터와 비정형 빅데이터의 융합 분석에 탁월한 성능과 분석 품질을 제공합니다. 기업 및 공공 빅데이터에 대한 시맨틱 검색/분석, 지능화뿐 아니라 플랫폼을 통해 IoT 센서와 생산 및 운영시스템 로그와 같은 스트림 빅데이터에 대한 실시간 분석, 예측 기능을 제공하고 있습니다. Bigdata Suite은 미래 IoT서비스 지능화와 운영 인텔리전스 구축을 포함해 데이터 기반 스마트 데이터 및 차세대 IT 시스템 구현을 위한 최적의 플랫폼입니다.
< Bigdata Suite 개념도 >
아래 그림에서 보듯이 빅데이터의 수집, 변환, 분석, 시각화, 의사결정 지원에 이르는 빅데이터분석 가치사슬 전체를 커버하는 최고의 플랫폼으로 구성되어 있습니다. 자연언어처리(NLP)와 인공지능기술, 기계학습(machine learning), 심층학습(deep learning), 추론기술, 분산병렬 처리와 같은 핵심 기반기술 등이 통합되어진 제품으로 빅데이터 라이프사이클 전체를 아우르는 단계별 엔진과 다양한 분석 및 시각화 기능 등을 사용자에게 제공합니다. 더불어 기존 Hadoop Eco System으로 구성되어진 빅데이터 플랫폼과도 유연하게 결합하여 최적의 지능형 빅데이터분석 플랫폼을 구성할 수 있습니다. 인메모리 맵리듀스 엔진인 SPARK, 실시간 스트림 데이터 처리를 위한 STORM과 UIMA 프레임워크와 같은 Opensource HADOOP ECO System을 구성하는 다양한 엔진 모듈 통합 구성이 가능합니다. 또한, 초대용량 실시간 데이터의 수집, 저장, 검색과 병렬/분산 분석 및 시각화의 모든 기능을 단 하나의 통합형 플랫폼에서 구현이 가능하고 강력한 확장(Scale-out and Scale-up)성을 지원합니다.
< Bigdata Suite 구성도 >
주요 기능
Bigdata Suite은 자연언어처리와 기계학습, 심층학습을 포함한 다양한 인공지능 기술과 고능률 분산병렬 빅데이터 처리 기술을 결합하고 실시간 데이터 수집, 변환, 저장과 분석, 시각화, 운영관리에 이르는 빅데이터 생명주기에 해당하는 기능을 아래 [표 #] 와 같이 제공하며, 지능화된 빅데이터분석을 위한 탁월한 안정성과 가용성뿐 아니라 사용자를 위한 강력하고 차별화된 다양한 지능형 분석 기능과 고품질의 분석 결과를 제공합니다.
주요 특성
지능형 실시간 빅데이터분석 통합 플랫폼 Bigdata Suite 제품을 구성하고 있는 주요기술이 반영되어진 엔진들은 규모, 다양성, 속도, 가치 측면에서 전통적인 기술과 방법으로는 다루기 어려운 데이터를 효과적으로 처리할 수 있게 제품화 되어 있으며, 비용대비 효율적으로 데이터를 처리, 분석, 표현함으로써 사용자들에게는 데이터 생태계의 가치사슬(데이터의 수집·저장·유통·활용)을 기반으로 데이터기반 시장을 통해 경제적 가치(신제품·서비스, 일자리 등) 창출할 수 있습니다.
주요 경쟁력
지능형 실시간 빅데이터분석 통합 플랫폼 Bigdata Suite 제품은 인공지능 기술(심층학습: deep learning)과 빅데이터 기술(기계학습: machine learning) 등이 융합되어 생산되어진 국내 최초 제품입니다. Bigdata Suite은 하둡 생태계의 통합연계 없이 전 산업군에서 지능형 빅데이터분석을 수행할 수 있는 AI 기반 End-to-End One stop 실시간 빅데이터분석 통합 플랫폼입니다.
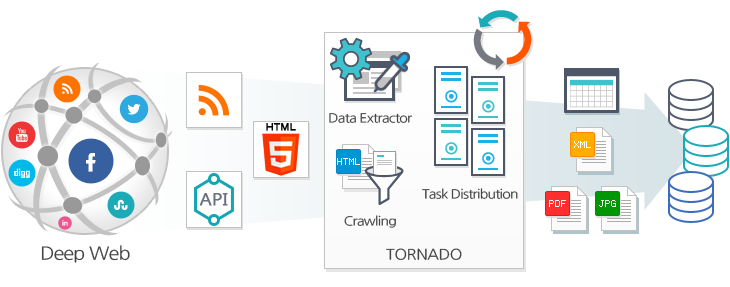
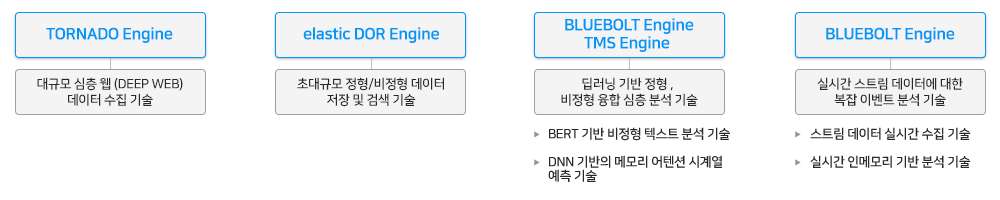
수집 엔진Tornado
빅데이터 처리의 시작은 데이터 생성 또는 수집이라고 할 수 있습니다. 전통적인 데이터베이스(DB) 환경에서는 외부에서 데이터를 가져오기보다는 DB의 프론트엔드인 애플리케이션에서 데이터가 생성되면서 처리가 시작되어지고, 반면 빅데이터는 내부에서 데이터가 생성되기보다는 외부의 데이터를 가져오면서 처리가 시작되어집니다. 빅데이터 환경에서 데이터 처리는 데이터 수집에서 시작한다고 할 수 있습니다.
빅데이터수집 엔진(Tornado)은 능동적인 방식과 수동적인 방식 둘 다 고려한 빅데이터수집 엔진으로 방대한 딥웹(Deep Web)과 SNS, 쇼핑 사이트, IoT, 스트리밍 데이터 등의 다양한 산업군에서 생성되는 빅데이터에서 사용자가 원하는 빅데이터를 실시간 자동, 병렬 수집이 가능한 강력한 빅데이터수집 처리 엔진입니다. 실시간 소셜 빅데이터분석, 경쟁자 분석, 시장 및 제품 분석, 위험 관리 및 고객 목소리 분석을 위한 최적의 빅데이터수집 환경을 제공하고 있습니다.
데이터의 유실과 중복 방지, 데이터 압축, 데이터 정형화, 저장된 데이터의 암호화, 무결성 검증, 사용자 편리성 등을 고려하여 보다 강력한 웹 수집 기능뿐 아니라 가려져 있는 웹 페이지로부터 빅데이터를 자동 추출하고 변환 저장합니다. 웹 데이터뿐 아니라 뉴스, RSS, 트위터, 페이스북 등의 소셜 빅데이터수집이 가능한 수집엔진으로 현존하는 가장 강력한 대용량 빅데이터수집 엔진입니다.
< 빅데이터수집 엔진 개념도 >
주요 특징
주요 기능 및 사양
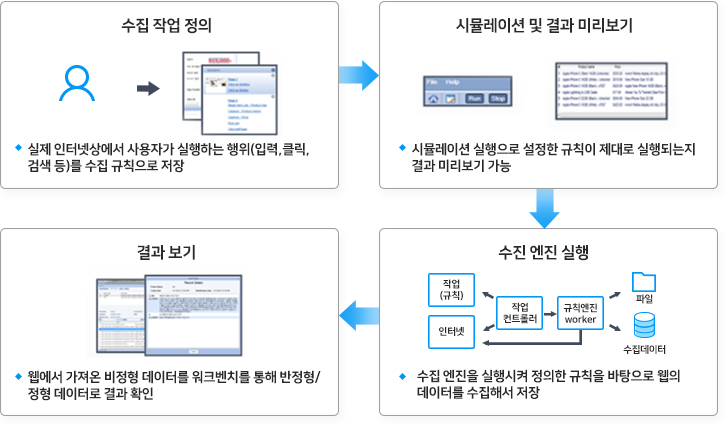
정형 및 빅데이터의 지능형 융합 분석에 필요한 다양한 형태의 내•외부 데이터 수집 처리를 하기 위하여 Big Data Suite의 빅데이터수집 엔진(Tornado)은 사용자 시나리오 기반 수집, RSS 기반 수집, 심층 웹 수집, 메타 검색 수집, 소셜미디어 수집, OpenAPI 수집 기능을 제공합니다. 사용자가 정의한 수집 업무를 수집 엔진 내부 시뮬레이터를 통해 수집이 의도한대로 동작하는지 테스트해 수행할 수 있으며, 실제 운영 시 수집이 실행되는 동안 실시간으로 수집 결과를 모니터링 할 수 있는 스케줄링 기능, 상태 모니터링 기능, 운영관리자 기능을 제공하고 있습니다.
< 수집 엔진 동작 절차 >
주요 엔진 화면
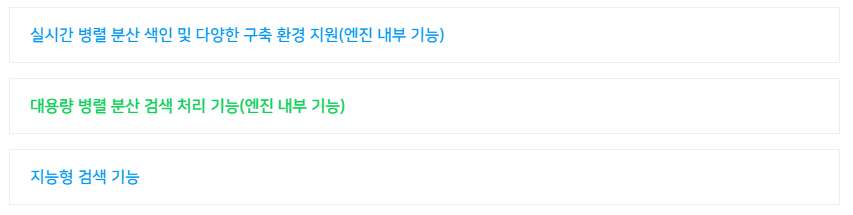
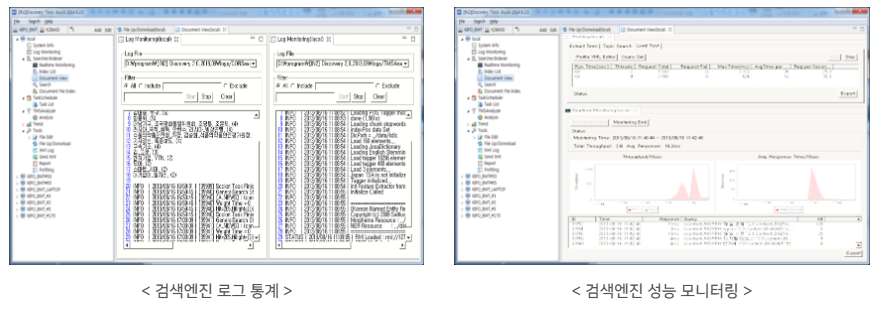
시맨틱 검색엔진Discovery
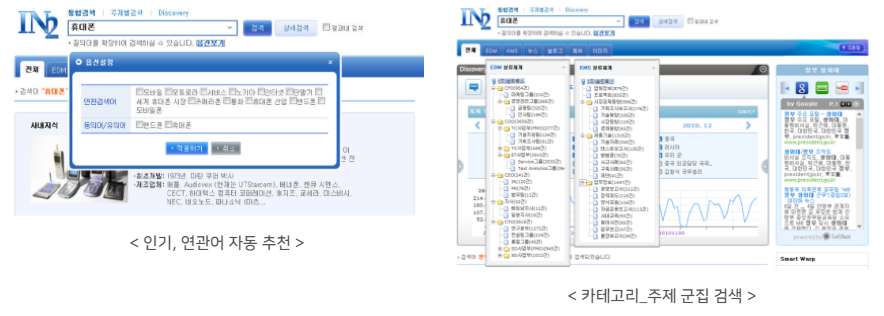
기계학습(Machine Learning)과 딥러닝(인공신경망)에 기반을 둔 인공지능기반 검색 엔진으로 단어와 문서의 의미를 기계가 스스로 이해할 수 있는 지능형 시맨틱 검색엔진(DISCOVERY)입니다. 특징학습(Feature Learning)이 가능한 기계학습 알고리즘을 적용하여 데이터 수집을 통해 특징을 학습함으로써 검색성능 향상과 사용자가 원하는 검색 결과를 제공합니다. 또한 단어와 문서의 의미를 기계가 스스로 이해할 수 있는 시맨틱 검색 솔루션으로, 입력한 키워드의 의미까지 스스로 판단해 검색 가능한 딥 서치(Deep Search) 기능을 내장하고 있습니다.
< 지능형 시맨틱 검색 엔진 개념도 >
Big Data Suite에서 기본적으로 활용하고 있는 저장소는 병렬/분산 저장이 가능한 빅데이터 저장소(GFS - GLORY-FS)를 적용하고 있습니다. 비용적인 측면에서의 효율성, 지속적으로 증가하는 데이터의 수용, 빈번하게 발생하는 장애에 대한 대처, 관리의 편리성, 신속한 입출력 성능, 데이터 최적 배치, 효과적인 캐시 사용, 부하 집중에 대한 유연한 대처, 데이터에 대한 보안 등과 같이 대용량 분산 파일 시스템이 갖추어야 할 사항들을 집약하고 있는 기본적으로 적용하여 구성되어져 있습니다.
주요 특징
지능형 시맨틱 검색 엔진 주요 특징
기업 내에 분산된 많은 양의 DB뿐 아니라 외부 소셜 빅데이터, 센서 및 로그 데이터, DOC, PPT, XLS, HWP 등의 오피스 문서를 포함한 초대용량 빅데이터를 특징학습을 통하여 검색 효율성 극대화 및 탁월한 검색 품질 성능을 갖춘 지능형 빅데이터 전용 시맨틱 기반 검색 엔진입니다.
빅데이터 저장소 주요 특징
수천에서 수만 대의 저비용 서버들을 이용하여 저장 공간 구축을 할 수 있는 분산파일시스템으로 장애에 대한 효율적인 통제 능력과 높은 입출력 처리 성능을 갖춘 대용량 데이터 처리를 위한 분산 파일 시스템입니다. GFS는 다음과 같은 주요 특징들을 가지고 있습니다.
주요 기능 및 사양
검색 서비스의 개발 편의성 및 표준화된 데이터 처리를 통해 검색 서비스 인터페이스 기능을 제공하여 효과적인 연계 서비스 구축으로 다양한 시스템의 사용자에게 다양한 검색 기능을 제공합니다.
주요 엔진 화면
텍스트마이닝 엔진TMS
텍스트마이닝 엔진은 대용량의 내·외부 비정형 데이터에 대하여 데이터의 특성, 의미와 연관성을 파악하여 의미기반 검색, 정보 재조직화, 다차원 분석을 수행함으로, 숨은 지식을 발견하고 이를 통하여 높은 지식활용, 고객관리, 위험관리, 연구개발 등의 올바른 의사결정을 할 수 있도록 숨은 지식을 발굴하여 가치화 할 수 있는 다양한 비정형 데이터 분석 기능을 제공합니다. 방대한 문서 및 정보에서 고품질의 정보 추출, 관계 추출, 자동 정보(문서) 분류, 자동 정보(문서) 군집, 자동 정보(문서) 요약 및 지능형 비정형 데이터 분석 기능 등으로 구성되어 있으며 지식정보의 검색, 분석 및 활용에 소요되는 시간을 획기적으로 단축시키는 지능형 비정형 빅데이터분석 엔진입니다.
< 텍스트마이닝 엔진 구성도 >
주요 특징
주요 기능 및 사양
자연어 처리 기능
비정형 데이터 가공을 위한 모든 고정밀 언어분석기들은 기계학습과 인공신경망 기술이 적용되어 있으며, 사전과 규칙을 통해 각 도메인별로 품질을 최적화할 수 있는 기능입니다.
< 자연어처리 기능 >
정보(문서) 자동 분류 기능
방대한 양의 비정형 빅데이터(정보 및 문서)에 대하여 사전 정의한 분류체계(카테고리) 별로 자동으로 실시간 계층 분류하는 기능으로 문서 분류에 학습 및 규칙 기반을 동시에 사용할 수 있는 혼합형 분류 기능입니다.
주요 엔진 화면
스트림분석 엔진BlueBolt
실시간 스트림 빅데이터분석 엔진(BlueBolt)은 다양한 장비와 생산라인의 로그, 센서 데이터와 같은 실시간 머신 데이터뿐 아니라 다양한 소스의 비정형 휴먼데이터를 융합 분석할 수 있는 실시간 스트리밍 데이터 분석 엔진입니다. 스트림 빅데이터의 실시간 인메모리 분석과 복잡한 이벤트 처리(CEP)를 통해 보안, 안보상의 이상 징후를 감지하거나 생산 라인의 문제 예측과 최적화 체계를 갖추는 것을 가능케 합니다. 특히 강력한 분산 인메모리 분석 기능은 대규모 서비스 시스템 운영/관리, 이상거래탐지(FDS; Fraud Detection System) 및 컴플라이언스와 eDiscovery를 포함한 운영 인텔리전스 (OI; Operational Intelligence) 구현을 위한 세계 최고의 성능을 제공하고 있습니다.
다양한 형식의 스트림 데이터(비정형, 반정형)를 실시간으로 수집·정제를 통하여 실시간으로 복잡한 조건의 질의 및 분석을 수행합니다. 분석한 결과들을 대시보드로 구성하여 실시간 모니터링 및 공유를 할 수 있으며 특정 조건에 일치하는 패턴이 발생하면 외부에 알림 기능을 수행합니다.
주요 엔진 화면
인지분석 엔진CAS
데이터 분석 관점에서 ‘인지’는 정형화된 규칙과 사물을 표현할 때 어떤 특징으로 표현할지 찾는 것을 말합니다. 솔트룩스의 인지분석 엔진(Cognitive Engine)은 컴퓨터가 사람처럼 학습을 통해 데이터에 대한 다양한 관점을 인지하거나 예측할 수 있는 인공지능 기술이 융합 적용된 기계학습(Machine Learning) 및 심층학습 (Deep Learning) 기반의 세계 최고의 인지분석 엔진입니다.
인지분석 엔진(Cognitive Engine)은 수집된 대용량의 내·외부 빅데이터를 기계학습 및 심층학습 기반으로 사람이 찾지 못하거나 사람이 분석하기에 어려운 데이터의 특성, 의미와 데이터 간의 연관성 분석 등을 빠른 속도로 찾아낼 수 있습니다. 더 나아가 초대용량 데이터에 대한 복잡계 분석, 음성과 텍스트 간의 융합분석, 이미지와 텍스트 간의 융합분석 기능을 제공합니다.
< 인지분석 엔진 - Cognitive Engine 구성도 >
주요 특징
주요 기능 및 사양
기계학습 및 심층학습을 통한 개체명 인지분석, 감성 인지분석, 지식/소셜 네트워크 분석, 음성인식 융합분석, 이미지 인식 융합분석 등 데이터 속의 의미관계망 분석을 통해 심층 분석 기능을 제공합니다.
개체명 인지분석 기능
기계학습 기반의 개체명 인지분석 기능은 데이터에서 개체(회사이름, 사람이름, 지역 명칭, 날짜, 시간, 금액)를 자동으로 추출(경계 구분)하고 추출된 개체의 종류를 분류를 통하여 개체들 간의 연관 관계를 실시간 자동 분석을 할 수 있는 기능입니다.
< 개체명 인지 분석 기능(실 구축 화면 - 언론진흥재단) >
감성 인지분석 기능
기계학습(Machine Learning)과 심층학습(Deep Learning) 기반 형태소, 문장구조, 개체명, 의미 등을 파악하여 토픽 별 감성 분석, 긍/부정 트렌드 분석을 처리하는 고품질, 고정밀 감성 분석(Sentiment Analysis) 기능입니다.
< 감성 인지 분석 기능 >
지식/소셜 네트워크 분석 기능
초대용량 웹, 소셜미디어, 이메일 및 방대한 기업이 보유하고 있는 데이터로부터 시맨틱 소셜 네트워크를 추출해 그 구조를 분석하고, 네트워크에 흐르는 지식과 상호 영향력을 기계학습 기반의 심층분석을 통하여 중심성분석, 군집분석, 최단경로 분석, 핵심 플레이어 분석, 주제별 핵심 노드 분석, 주제별 연관 노드 분석, 연관 주제별 핵심 노드 분석 등 지식네트워크 상에 유통되는 데이터에 대한 실시간 분석을 할 수 있는 기능입니다.
< 지식/소셜 네트워크 분석 기능 – 통계분석 & 중심성분석 >
음성인식+텍스트 융합 분석 기능
사용자의 실시간 음성데이터를 입력 받아 텍스트로 변환 후 비정형 빅데이터분석 기능과 연계하여 분석을 수행하는 기능과 사용자가 보유하고 있는 테스트 데이터와 음성인식을 통한 텍스트로 변환되어진 데이터 간의 융합 분석하는 기능입니다.
< 실시간 음성인식을 통한 텍스트 분석 – 이슈 분석 >
주요 엔진 화면
시각분석 엔진Rainbow
시각분석 엔진(Rainbow)은 빅데이터와 그 분석 결과를 다양한 관점에서 시각화 함으로 숨겨져 있는 패턴을 발견하고, 미래를 예측, 이해할 수 있도록 지원합니다. 단순한 개별 데이터의 시각화뿐 아니라, 서로 다른 데이터를 융합, 재구성하고 동적 대시보드를 통해 시각적분석을 가능하게 합니다.
< 시각분석 엔진 개념도 >
워크벤치를 통해 다양한 시각화 라이브러리를 통해 표현되는 데이터들은 엔진 내부 임시저장소를 통해 관리되며 웹, 기업 포털 및 소셜미디어에 퍼블리싱이 가능합니다. 전통적인 BI(비즈니스 인텔리전스)와 시각화 도구의 한계를 넘어, 빅데이터로부터의 새로운 통찰력을 얻고, 데이터를 통해 문제 해결과 답을 얻도록 돕는 최고의 빅데이터 시각적분석 엔진입니다.
주요 특징
다양한 데이터 소스와 파일 포맷 지원
주요 기능 및 사양
다양한 형식의 데이터소스에 연결을 하여 선택된 데이터에 대하여 연산, 필터링 및 서로 다른 데이터 소스 간의 결합이 가능하며 최종 정제된 데이터를 가지고 인터렉티브 한 시각화 요소들을 쉽게 생성하는 것이 가능 합니다. 또한 웹 서버로의 퍼블리싱을 통하여 생성한 시각화 요소를 웹 상에서 확인하거나 다른 사람들과 공유를 할 수 있는 기능을 제공합니다.
< 시각분석 엔진 동작 프로세스 >
주요 엔진 화면
적용사례
국가단위의 빅데이터분석 플랫폼 구축
공간빅데이터 체계 구축 사업 - 국토교통부 - 국토교통부장관 표창 수상
행정정보와 민간정보 등 공간데이터 기반 정형·비정형 빅데이터 및 텍스트 데이터를 융합하여 생산성 있는 지능형 공간데이터를 구축하였으며, 이를 바탕으로 다양한 분석 모델과 템플릿을 제공하여 사용자가 웹 환경에서 쉽고 빠르게 분석모델을 활용 및 분석을 할 수 있는 워크플로우 기반 분석 도구를 제공하였습니다. 또한 공간빅데이터 기반 다목적 공간빅데이터분석 표준 플랫폼 구축 및 서비스 환경을 제공하여 국정현안에 선제적으로 대응하고 미래전략을 수립할 수 있도록 공간정보의 특성을 고려하여 지능형 공간빅데이터를 구축하고 스마트 행정을 실현할 수 있는 기틀을 마련하였습니다.
< 국토교통부 - 공간빅데이터 체계 포털 >
① 사업의 내용
(융합 DB 구축) 융합데이터 서비스를 통해 다양한 융합DB의 결과를 Dash board형태로 제공하여 사용자가 공간 데이터를 보다 쉽게 이해하고 접근할 수 있도록 하였으며 다양한 유형의 결과값을 대시보드 형태로 제공
(데이터서비스 개발) 융합자료와 기초자료로 데이터셋을 분류하여 제공하는 데이터 서비스로 조회를 통하여 관련 데이터를 다운로드 할 수 있고, 융합DB의 시계열 정보를 효과적으로 활용할 수 있는 화면 분할 방식의 시각화 서비스를 제공
(분석 플랫폼 구축 및 시각화 서비스 개발) 공간정보 및 공간빅데이터에서 제공되는 데이터와 공간빅데이터분석도구에서 제공하는 공간라이브러리를 활용하여 분석을 지원하는 공간빅데이터분석 플랫폼 구축과, 공간하둡(Spatial Hadoop) 기반의 분석결과를 지도 위에 시각화하여 표출할 수 있는 시각화 서비스 제공
(소셜 공간분석 서비스 개발) 비정형데이터를 문장단위로 감성분석하여 존재하는 위치정보와 결합하고 이슈와의 관계를 파악하고 지역에 따른 주요토픽, 어휘 트렌드를 분석하여 지도 위에 시각화하여 표출할 수 있는 서비스 제공
< 공간빅데이터분석 기능 >
② 적용 기술 및 솔루션
Big Data Suite 제품 적용 정형·비정형 공간빅데이터 기반의 스마트 데이터 및 차세대 빅데이터분석 플랫폼 구현을 위하여 One stop 실시간 공간 빅데이터분석이 가능한 Big Data Suite 제품 적용
HDP 3.2 제품 적용 호튼웍스에서 Package한 HDP 3.2를 적용하여 Big Data suite 제품과 Hadoop Eco System 연계를 통하여 최적의 공간 빅데이터분석 플랫폼 구성
③ 제품 선정 당위성
Big Data Suite Pilot을 통한 제품 품질의 우수성 및 탁월한 성능 평가 1차 구축 시스템과 Big Data Suite으로 구성한 Pilot시스템을 국토교통부 주관 외부전문가를 통하여 빅데이터 전주기에 해당하는 전 단계별 성능 및 품질 테스트 수행 후 Big Data Suite Pilot 시스템의 품질 및 성능 우수성 평가
④ 주요 성과
국토교통부 산하 구축 사업 중국토교통부장관 표창 수상
과학행정 구현 및 맞춤형 서비스 제공을 위해 공간정보를 활용한 공간 빅데이터 체계를 구축하여 범정부적 활용을 지원
공간 빅데이터의 공통활용 기반을 조성하여 중앙행정기관, 지자체, 공사공단 등 공공부분에서 공간정보를 활용한 합리적이고 객관적인 정책수립을 지원하여 현안사항 해결 지원
부동산, 교육, 복지, 범죄, 재난 등 복잡한 사회․경제적 현안에 선제적 대응
과학적 공간분석기법을 활용한 미래국가 전략 수립 및 의사결정 지원
공간 빅데이터를 활용한 다양한 민간 활용서비스 모델 개발, 확산을 통해 신산업 및 일자리 창출 등 공간정보산업 진흥 도모
공간빅데이터 체계는 사용자 활용성을 고려하여 다양한 형태의 템플릿과 웹 환경에서 사용자가 보다 쉽고 빠르게 분석 모델을 개발할 수 있는 환경을 제공
이를 통해 사용자가 목적에 따라 데이터와 분석 기능을 조합하여 새로운 분석모델 개발 및 분석 결과 도출이 가능한 기능 제공
분석모델의 결과는 공간하둡 기반의 위치정보를 활용한 공간 시각화, 화면분할을 통한 시계열 정보화를 통하여 과거의 정보, 미래예측을 포함한 분석결과를 한눈에 파악할 수 있는 서비스 제공
신기술 센싱 및 예측 분석 플랫폼 구축
삼성전자 신기술 센싱 시스템 구축 – 삼성전자 & 삼성반도체
삼성전자 및 삼성반도체 내부 KMS에 축적되어 있는 지식정보들과 함께 외부 KISTI (한국과학기술정보연구원)와의 MOU 계약을 통해 공급받게 된 해외학술자료, 국내 학술회의 정보, 각종 연구보고서, 해외과학기술 동향분석 정보 등 대량의 기술문서, 국내외 IT 뉴스, IT전문리뷰/블로그, 기술잡지 등을 수집 및 내/외부 지식정보 통합을 통하여 미래 기술/사업 불확실성에 대한 리스크 조기 감지 체계를 구축하였습니다.
또한 신기술 정보 자동수집 및 분석 체계를 구축함으로써 신기술 및 응용분야에 대한 조기 신기술 센싱 능력 강화를 통해 연속 기술의 한계, 비연속 기술 등장에 따른 사업 리스크 대응, 사업 리스크 보완을 위한 벤처투자, M&A 전략 수립 등 신기술 센싱의 다양한 분석 및 예측 기능을 통하여 내부 데이터 기반의 의사결정 지원을 할 수 있는 기틀을 마련하였습니다.
< 삼성전자 - 신기술 센싱 시스템 >
① 사업의 내용
(데이터 수집 체계 구축) 내외부 다양한 형태의 정형데이터, 비정형데이터에 대한 다양한 수집 기능이 적용되어진 수집 체계 구축을 통하여 신기술 센싱, 예측 분석을 위한 통합 DB 구축
(데이터 모델링 및 지식베이스 구축) 신기술 센싱의 품질 확보를 위하여 내부에서 생성되는 지식뿐만 아니라 외부에서 생성되고 수집되는 기술문서 및 소셜 데이터(뉴스, 블로그 등)에서 다양한 연관성 정보를 추출하기 위하여 삼성전자 신기술 센싱을 위한 다양한 데이터 모델링 구축을 하였으며, 이를 통하여 기술 및 기업정보 지식베이스(인물/논문/특허 연관성, 기술/기업/인물 연관성, 기업/ 투자기관/인물 연관성 등)를 구축
(신기술 센싱 플랫폼 구축 및 분석 서비스 개발) 삼성전자 내부 지식정보들과 외부에서 수집되어지는 데이터를 수집, 저장, 가공, 분석 및 시각화를 지원하는 신기술 센싱/예측/분석 플랫폼 구축을 통하여 다양한 대용량의 데이터에 대한 기업/인물/기술/논문/언론 등에 대한 상호연관성 분석, 지식 트렌드 분석, 지식정보 네트워크 분석, 실시간 신기술 센싱/예측 분석 등 다양한 분석 기능의 결과에 대한 시각화하여 표출할 수 있는 서비스 제공
② 적용 기술 및 솔루션
Big Data Suite 제품 적용 내부 지식정보 및 외부 기술데이터 기반의 지능형 신기술 센싱, 예측 분석 플랫폼 구현을 위하여 실시간/배치 분석이 가능한 Big Data Suite 제품 적용
③ 제품 선정 당위성
PoC를 통한 제품 성능 및 품질 테스트 수행의 우수성 검증
삼성전자 KMS를 위한 신기술 센싱 플랫폼 구축에 적용되어질 빅데이터분석 플랫폼 사전 검증을 위하여 POC를 3차에 걸쳐 수행 후 제품의 성능 및 품질의 우수성으로 인해 선정
국문 및 영문 데이터 대상으로 데이터 수집, 저장단계, 분석단계, 시각화 단계에 각 단계별 시스템 성능 및 분석 성능 등 다양한 검증을 통하여 지능형 신기술 센싱, 예측 분석 플랫폼 구축을 위하여 Big Data Suite 선정
④ 주요 성과
단순 검색 기능으로는 개별 기술, 혹은 개별 키워드에 대한 단순 나열의 결과 밖에는 얻을 수 없었고 이 제한된 기능으로 전체 기술네트워크를 바라보거나 기술분석 트렌드를 알아내는 것은 불가능에 가까운 일이었으나, 구축한 신기술 센싱 시스템으로 인해 나무가 아닌 숲을 바라볼 수 있는 능력과 적용기술 혹은 관심기술의 트렌드 정보의 제공이 가능해 거대하고 개별적인 기술이슈를 가진 삼성전자 조직 구성원들의 기술 탐색 욕구를 충족시킬 수 있었습니다.
이는 기존 시스템 Open 이후 기존 KMS 접속 및 사용자를 3~5배 증가시켜 삼성전자 지식관리 활동을 비약적으로 증가 및 개선시킨 효과를 가져왔습니다.
미디어 컨텐츠 분석 플랫폼 구축
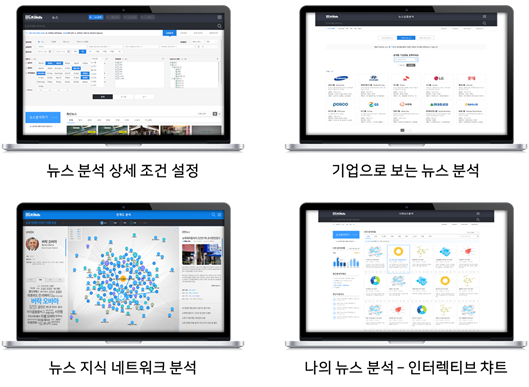
뉴스 빅데이터분석 시스템 구축 - 한국언론진흥재단
국내 각 언론 기관들이 수십 년에 걸쳐서 구축한 뉴스 미디어 콘텐츠에 대한 고부가가치화 및 지식화를 통한 저널리즘 서비스의 획기적 혁신을 통하여 차별화된 대정부/대국민 서비스로 발전시키기 위해서 방대한 양의 뉴스 데이터를 체계적으로 분석할 수 있는 플랫폼을 구축하였으며 지능형 분석을 위해 뉴스 빅데이터 관련 메타데이터 등 분석 데이터구축, 사용자를 위한 다양한 분석 서비스 및 관리 체계를 구축하여 미디어 기반의 지능형 분석, 융합, 예측 서비스 등 고품질의 저널리즘 정보 생산 주체인 언론 기관들이 향후에 보다 수준 높은 차세대 미디어 콘텐츠를 지속적으로 도출하고 자생적으로 유통 지원 혁신을 위한 기틀을 마련하였습니다.
< 한국언론진흥재단 - 뉴스빅데이터 분석 서비스(BIGKinds) >
① 사업의 내용
(뉴스 빅데이터 DB 구축) 국내 종합일간지, 경제일간신문, TV방송뉴스, 인터넷신문, 영자일간지, 지역주간신문과 고신문 및 90년대 이전신문 등과 국외 해외뉴스를 포함한 최대 규모의 기사 DB 구축
(뉴스 빅데이터분석 플랫폼 구축) 뉴스 빅데이터를 분석 위하여 한국어를 포함한 영어권 언어 분석이 가능한 지능형 자연어처리엔진, 기계학습기반 비정형 텍스트분석 엔진, 의미기반 검색엔진 등 뉴스 빅데이터 심층 분석 처리를 위한 플랫폼을 구축
(뉴스 빅데이터분석 서비스 개발) 뉴스 빅데이터를 활용하여 의미기반 뉴스 검색 기능을 통하여 일반인을 위한 빅카인즈 검색 서비스와 전문가를 위한 빅카인즈 프로 서비스를 제공
뉴스 심층분석을 통하여 뉴스와 주가 지수 간의 연관 정보 및 예측 분석 기능, 뉴스기사를 분석하여 인용문을 추출하고 해당 인용문의 정보원을 분석하는 뉴스 정보원 분석(네트워크) 기능, 트렌드 리포트 기능, 각 국의 정치뉴스를 분석하여 특정 이슈에 대한 차이를 볼 수 있는 해외 뉴스 심층 분석 기능, 국가별 언론보도에 대한 트렌드 분석, 연관어 분석, 네트워크 분석 등 사용자에게 다양한 분석 기능 등 다양한 분석 기능을 제공
< 뉴스 빅데이터 분석 기능 >
② 적용 기술 및 솔루션
Big Data Suite 제품 적용 국내/해외 뉴스 콘텐츠 기반의 비정형 뉴스 빅데이터분석 플랫폼 구현을 위해 One stop 실시간 미디어 콘텐츠 빅데이터분석이 가능한 Big Data Suite 제품의 적용
Apach SPARK, STORM, KAFKA 등 적용 OpenSource Apach SPARK, STORM, KAFKA 등을 뉴스 빅데이터 플랫폼에 적재적소에 반영하여 Big Data Suite 제품과 연계를 통하여 최적의 품질을 보장하는 뉴스 빅데이터분석 플랫폼 구성
③ 주요 성과
대규모 뉴스 데이터구축 및 분석을 통하여 국가적으로는 중요한 역사적 자산 축적 및 사회변화 예측 및 정책 입안·사업 기회 포착에 기여
또한 경제적인 측면에서는 향후의 판세나 정황을 예측하고 대처할 수 있는 창조 경제 브레인 역할을 수행할 수 있는 기틀 마련
고품질의 저널리즘 정보 생산 주체인 언론 기관들이 향후에 보다 수준 높은 차세대 미디어 콘텐츠를 지속적으로 도출하고 자생적으로 유통할 수 있는 혁신적 시스템 기반 마련
뉴스빅데이터분석 체계를 활용한 글로벌 뉴스(영문, 일문) 분석 시스템 및 특정 이슈에 대한 국가별 언론보도의 차이 분석 서비스 제공을 통하여 글로벌 뉴스 분석 서비스 영역의 선두사례로 발전
뉴스 활용가치에 대한 사회적 인식 제고 및 이에 상응한 언론사 콘텐츠 기반 수익모델 창출에 기여
방대한 뉴스 데이터와 개별 사용자, 개별 기관의 특성과 성향을 분석하여 맞춤형 뉴스 및 관련 정보 제공
금융 데이터 & 실시간 VOC 분석 플랫폼 구축
지능형 실시간 VOC 분석 및 TA 분석 시스템 구축 – 농협은행
고객의 디지털 채널 활용 증가와 지능형 서비스 요구의 지속적 상승이 예상되어, AI기반 서비스 확대를 통한 고객 만족도 및 운영 효율성을 높일 수 있도록 기존 시스템을 고도화하고 개선하는 것을 목표를 두고 콜센터 AI 빅데이터 시스템을 구축하였습니다.
농협은행 고객행복센터에서 매일 발생되는 전화 상담 내용을 기록 저장하고 분석하는 상담 빅데이터분석 시스템을 실시간 음성처리, 언어분석 처리, 대용량 분산 환경을 적용하였으며, 실시간 TA(Text Analysis) 분석 서비스가 가능한 구조로 개발하여 적시, 적소에 상담 데이터 분석 결과를 제공하였으며, 다양한 목적과 관점에서 분석하고 통찰할 수 있는 지능형 VOC 분석 및 TA분석을 위한 기반을 마련하였습니다.
< 농협은행 - 지능형 금융 데이터 분석 >
① 사업의 내용
(데이터 저장 및 운영 환경 개선) 수집되는 상담 빅데이터는 메시지 큐에 저장되고 분산 어플리케이션을 통해 색인 및 빅데이터 저장소에 저장되면 텍스트 분석을 통한 서비스로 구성
(지능형 지식관리시스템 구성) 신규 KMS(지능형 지식관리 시스템)을 통해 구축/관리되는 지식정보가 지식베이스로 동시에 관리되고, 질의응답 시스템에 자동 배포 가능한 구조가 구성
(TA 서비스 구성) 이슈 클라우드 및 이슈 트렌드 분석 기능 제공
이슈 키워드에 대한 감성분석 기능을 제공
연관 토픽 분석에 대한 네비게이션 기능 제공
상담결과를 주제별로 자동 군집하는 기능 제공
< 지능형 VOC 분석 및 TA 분석 기능 >
② 적용 기술 및 솔루션
Big Data Suite 제품 적용 상담데이터 수집계층, 메시지계층, 빅데이터 저장계층, 빅데이터 색인계층, 활용서비스 계층 등으로 구성할 Big Data Suite 제품 적용
Apach SPARK, STORM, KAFKA 등 적용 OpenSource Apach SPARK, STORM, KAFKA 등을 뉴스 빅데이터 플랫폼에 적재적소에 반영하여 Big Data Suite 제품과 연계를 통하여 최적의 품질을 보장하는 지능형 금융 빅데이터분석 플랫폼 구성
③ 제품 선정 당위성
Big Data Suite의 대용량 빅데이터수집에 대한 무결성을 보장하며, 실시간 데이터 송수신에서의 유실을 방지합니다. 또한 분산 처리 환경과 인메모리 분석을 통해 대용량 집계 및 분석 처리시에도 빅데이터 시스템의 성능을 보장하는 제품 선정
지속적으로 증가하는 상담 데이터의 실시간 분석과 배치 분석 모두 수용할 수 있는 분석 플랫폼 체계 필요성에 충족하는 제품 선정
인메모리(in-memory) 기반의 집계 및 통계 분석과 실시간 색인 및 분산 처리를 통해 고성능의 빅데이터분석이 가능한 제품 선정
③ 주요 성과
사용자 증가로 부하가 집중될 수 있는 고객 집중 상담 시간에도 원활한 서비스가 가능하고, 향후 지속적인 데이터 증가나 서비스 확대에도 시스템 인프라 확장이 유연한 구조로 구성
TA 분석 기능 및 서비스 개선으로 실시간 이슈 분석 및 상담 품질 평가 기능 고도화
상담 이슈에 대한 검색, 통계, 트렌드 분석, 연관성 분석 등이 연관성을 가지고 주제를 확장하여 심층 분석될 수 있도록 UI를 개선하고 분석 결과를 시각화서비스 제공
상담사의 고객 상담을 실시간으로 모니터링 하거나, 상담 결과에 대한 품질 평가의 일부를 시스템으로 자동화함으로써, 오상담이나 부적절한 대응을 적시에 발견하고 개선하여 고객 상담의 만족도 향상
음성데이터를 텍스트로 변환하고, 비정형 텍스트를 분석하여 결과를 제시해야 하는데 이를 대량으로 실시간으로 처리할 수 있는 지능형 인지분석 기능 제공
지능형 통합 검색 시스템 구축
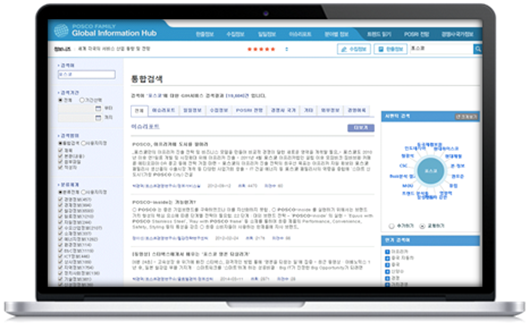
포스코 GIH(Global Information Hub) 구축 사업 – 포스코 경영연구소(POSRI)
GIH 프로세스를 효율적으로 지원하고 패밀리사의 전략적 의사결정 지원을 위해 IT 시스템 구축이 필요. 포스코 및 패밀리사에서 자체 관리하던 국내∙외 사외정보를 GIH에서 통합관리하고 분야별 전문가가 분석∙가공해 임직원에게 서비스하기 위한 포스코 패밀리 통합정보관리 네트워크를 구축하기 위함입니다.
GIH 내부정보와 외부 수집정보를 대상으로 정형/비정형 데이터에 대한 지능형 분석을 통해 관련 주제 및 이슈 키워드의 시맨틱 검색으로 보다 정확한 정보검색과 모니터링 능력을 극대화하고, 특정 주제에 대한 동향분석, 트렌드 분석, 연관주제 분석 등 축적된 비정형데이터를 대상으로 보다 입체적이고 의미 있는 분석 수행이 가능하게 하였습니다.
< 포스코 – 시맨틱 통합 검색 & 분석 >
① 사업의 내용
(의미기반 지능형 통합 검색 체계 구축) 사용자가 질의하거나 선택한 키워드 (토픽)에 대하여 키워드를 포함한 문서 중 중요한 문서의 상위 100건의 문서를 실시간 분석하여, 검색어와 가장 밀접한 관계를 가지고 있는 연관정보를 추출하여 방사형 트리 형태로 조회할 수 있는 지능형 검색 체계를 구축
(지능형 검색 기능 개발)
검색결과 클러스터링: 사용자 질의어에 대한 검색 결과 문서를 실시간 분석하여 문서 클러스터링 결과를 제공
인기검색어: 사용자가 검색한 검색어 이력을 통계적으로 추출하여 순위를 시각화하여 표출
자동분류검색: 정보(문서) 자동분류를 통해 분류가 되어진 데이터에 대하여 분류체계를 통한 검색을 할 수 있는 기능 제공
유사문서 검색: 특정문서와 유사한 문서를 다양한 출처에서 실시간으로 검색해서 제공
(지능형 트렌드 분석 기능 및 서비스 개발) CEO메시지와 정보니즈 데이터를 분석하여, 주요키워드를 기간 단위로 추출하여, 해당 기간 동안에 이슈가 되는 키워드를 추출하여 사용자들에게 다양한 챠트 형식으로 시각적분석 서비스를 제공
< 의미기반 지능형 통합검색 및 트렌드 분석 >
② 적용 기술 및 솔루션
Big Data Suite 제품 적용 GIH 내부정보와 외부 수집정보를 대상으로 정형/비정형 데이터에 대한 지능형 검색 및 데이터 분석을 위하여 Big Data Suite 제품의 빅데이터 저장/검색 엔진(DISCOVERY), 비정형 빅데이터분석 엔진(TMS)를 적용하여 구축
③ 제품 선정 당위성
GS인증, 행정업무용 SW인증, 신SW 상품대상, 대한민국SW대상 대통령상 수상을 국내 최고의 성능과 품질을 보장하는 빅데이터 저장/검색 엔진(DISCOVERY) 및 비정형 빅데이터분석 엔진(TMS) 선정
③ 주요 성과
포스코 패밀리 정보 경쟁력 강화 유용한 정보를 신속하고 정확하게 제공 분업 및 협업을 통해 패밀리간 정보 공유 최신 정보기술 활용을 통한 효율적 정보활용 및 업무생산성 증가
포스코 패밀리 정보 마인드와 문화 정착 정보 수집 및 활용을 통한 정보 마인드의 진화(형성→확산→정착) 기반 마련 정보 활동 모니터링과 피드백을 통해 변화관리 유도
전략적 Insight 정보 발굴 국내외 유의미한 정보의 체계적 축적 전략적 Insight정보를 활용한 의사결정 지원 신 사업 아이디어 발굴 및 경영 Risk 선제 대응
포스리 정보기반 분석역량 강화 포스리와 패밀리사간 효과적 커뮤니케이션과 의사결정 지원 기반 구축 국내외 현장의 Live한 정보취득으로 포스리 연구/과제 현장성 강화
빅데이터 기술소개
실시간 데이터 수집, 저장, 검색, 분석, 시각화에 이르는 빅데이터 라이프 사이클을 충족시키는 Big Data Suite 제품은 아래에서 제시하고 있는 주요 기술들이 반영되어 구성되어 있습니다.
(304100) 솔트룩스 - (1) 회사소개 & 인공지능 ( AI Suite , 적용사례 , 기술소개 )
saltlux
동사는 1981년 8월에 설립되었으며, B2B 및 B2G 인공지능·빅데이터 솔루션을 프로젝트 수주하여 구축 혹은 클라우드 기반으로 서비스 하는 사업을 영위.
동사의 주요 제품으로는 지능형 빅데이터 분석 플랫폼인 Big Data Suite와 인공지능 플랫폼인 AI Suite가 있으며, 각각 2019년 전체 매출액의 41.2%, 37.75%를 차지.
아웃바운드 컨택센터 자동화, 지능형 채용/HR 심사 등의 신규 사업 확장 계획.
회사소개
솔트룩스는 기계학습과 자연어처리 스타트업으로 2000년에 창업된 ㈜시스메타에 그 뿌리를 두고 있으며, 창업이래 인공지능과 빅데이터 기술의 한 우물을 파온, 국내 대표적인 4차산업혁명 원천기술 기업입니다. 자사는 창업 초기부터 원천기술 확보에 집중해 왔으며 2006년 솔트룩스로 기업명을 변경하고 인공지능 기술개발과 신시장 창출에 더욱 박차를 가해 왔습니다.
솔트룩스는 알고리즘 중심의 인공지능과 빅데이터 기술개발뿐만 아니라 인공지능 사업의 글로벌 경쟁력 확보를 위해 150억건 이상의 대규모 데이터를 축적, 자산화하고 끊임없는 혁신제품 출시와 해외 진출에 노력해 왔습니다. 자사의 이러한 노력은 118건의 기술 특허출원(PCT 포함)과 61건의 등록특허, 145건의 등록 소프트웨어 보유, 매년 20% 이상의 높은 매출 성장의 결실을 보이고 있습니다. 지난 19년간 인공지능과 데이터 부분에서의 기술, 인재, 경험의 축적은 최근 인공지능 기술의 성숙과 세계적 성장에 따라 솔트룩스와 자회사, 파트너, 고객 모두에게 큰 성장의 기회가 되고 있습니다.
솔트룩스 인공지능 기술의 차별성은 한마디로 ‘고정밀 앙상블 인공지능’으로 표현할 수 있습니다. 이는 다양한 기계학습(딥러닝) 기술과 지식그래프, 논리추론과 같은 상이한 AI 기술들을 융합함으로 구현되며, 대규모 데이터 수집, 분석, 학습 등의 빅데이터 및 데이터과학 기술이 뒷받침되어야 합니다. 축적의 시간을 통해 확보된 솔트룩스의 차별화된 인공지능과 빅데이터 기술에 대한 상세 소개와 그 상용 경쟁력 및 구체적 사업계획과 전망 내용을 담고 있습니다.
설립 배경
솔트룩스는 ‘세상 모든 사람들이 자유롭게 지식 소통하도록 돕겠다’는 기업 사명(mission statement)을 중심으로 사람과 사람뿐 아니라 사람과 기계, 기계와 기계가 상호 소통/협력 가능한 미래 원천기술을 개발하겠다는 일념으로 세명의 공동창업자에 의해 설립이 되었습니다. 설립초기에는 컴퓨터가 사람의 글과 말을 이해하기 위한 기계학습 기술 개발에 집중을 하였으며, 2005년부터는 지식공학(Knowledge Engineering)과 지식그래프(Knowledge Graph) 및 추론 기술에 대한 연구, 2010년부터는 심층 질의응답과 대화처리, 2015년 이후는 딥러닝 기반의 지식학습, 음성인식/합성 등에 많은 투자를 진행해 왔습니다. 솔트룩스의 기업 사명은 회사의 존재 이유가 되며 ‘올곧게 일함’, ‘혁신을 통한 공헌’, ‘행복과 성장 추구’로 정의된 핵심 가치는 솔트룩스 임직원이 일하는 방식과 이유를 설명하고 있습니다. 솔트룩스 임직원은 우리의 기업 사명과 핵심 가치가 우리의 고객의 성공을 넘어 사회와 인류의 보다 행복한 삶에 기여한다 믿고 있습니다.
브랜드 스토리
세상에 필요한 빛과 소금이 되겠습니다.
솔트룩스(SALTLUX)는 ‘SALT(소금)’와 ‘LUX(빛)’의 합성어로서, 새로운 지식기반 세상에 필요한 빛과 소금의 역할을 담당할 기업 철학을 내포하고 있습니다. 구체적으로 ‘SALT’는 변치 않는 도덕적 가치와 성실한 봉사의 정신 그리고 통화와 자본으로서 가장 오래된 화폐 기능 등 문화적 이미지를 상징합니다. 또한 ‘LUX’는 빠르게 변하는 지식과 정보를 손쉽게 제공하는 IT 기술로서의 빛과 따뜻하고 풍요롭게 변화하는 미래의 문명적 이미지를 상징하고 있습니다. 따라서 ‘SALT’는 기업의 내재 가치를, ‘LUX’는 기업이 제공하는 기술적 서비스를 뜻합니다.
기술 개요
솔트룩스는 향후 5년간 언어, 음성, 시각, 감성, 지식 등 각 AI 기술을 고도화하고, 하나의 앙상블 AI 플랫폼으로 융합, 발전시킴으로 현재 기계학습 기술의 한계를 극복한 세계 최고 수준의 차세대 인공지능 상용 기술의 확보를 목표하고 있습니다. 현재 솔트룩스가 보유한 국가 수준의 빅데이터 플랫폼 기술을 지구 스케일로 확장 고도화하고, 이를 통해 전세계 대상의 데이터 수집과 실시간 이슈 분석, 이상징후 조기 감지, 더 나아가 지능형 예측을 포함한 실시간 증강분석 기술의 상용화를 목표로 하고 있습니다. 지구 스케일의 빅데이터 증강분석 기술은 앙상블 AI기술과 결합되어 글로벌 AIaaS 통합 플랫폼을 구현하는데 중추역할을 하게 될 것입니다.
조직 구성
솔트룩스는 현재 5개의 사업본부 아래에 6개 그룹, 16개 팀, 대표이사 직속의 2개의 실과 경영자문위, 기술자문위로 조직이 구성되어 있으며, 2개의 해외 자회사와 1개의 국내 자회사를 별도 운영하고 있습니다. 경영자문위원회는 경영, 법률, IT산업 등의 분야에서 독보적인 경력을 쌓아온 국내 최고 리더 6명으로 구성되어 있으며, 솔트룩스의 경영전략에 대한 자문과 경영진에 대한 멘토의 역할을 하고 있습니다. 기술자문위원회는 국내외 최고의 AI 석학과 전문가로 구성되어 있으며, 솔트룩스의 기술과 제품에 대한 발전 방향을 제언하고 오픈 이노베이션을 통한 R&D 혁신을 지원하고 있습니다.
이경일 대표이사는 폭넓은 대내외 활동과 빅데이터 및 인공지능에 대한 기술전문성을 바탕으로 솔트룩스의 사업 비전과 성장 방향을 제시하며 솔트룩스를 이끌고 있습니다.
AI 및 빅데이터 분야에서 세계적으로 인정받는 AI & Big Data Guru
솔트룩스의 7명의 CXO와 3명의 연구위원은 각자의 사업/운영 영역에 대한 풍부한 경험과 전문성을 가지고 있습니다.
사업소개
사업 비전
솔트룩스의 기업 사명이 우리의 존재 이유와 목적을 설명한다면, 사업 비전은 우리의 사업 추구 목표와 방향을 제시합니다. 지난 2017년 솔트룩스는 2025년까지 글로벌 AIaaS (AI as a Service) 통합 플랫폼을 확보하고, "1억 명의 일상과 함께하는 AI 기업"이 되겠다는 새로운 기업 비전과 함께 기술, 제품, 사업 부분의 각 세부 목표를 수립하고 단계적 로드맵을 실천해 가고 있습니다.
사업 내용
솔트룩스는 지난 10년간 인공지능 고객센터 구축과 챗봇 고객응대 서비스를 포함한 인공지능 플랫폼 공급 사업과 공공 빅데이터 분석 플랫폼, 비정형 및 고객 목소리 분석 등을 위한 빅데이터 플랫폼 공급을 주요 사업으로 진행해 왔습니다. 주요 고객으로는 삼성전자, LG전자, 현대자동차를 포함한 국내대기업과 행자부, 국토부 등의 공공기관, 그리고 우리은행, NH농협은행 등의 금융기관뿐만 아니라 ANA항공, 미즈호은행 등 해외사업분야에도 폭 넓게 확대되고 있습니다.
최근에는 AI OpenAPI 서비스와 데이터과학 SaaS 서비스, 대규모 데이터 수집과 인지분석 등의 클라우드 기반한 구독형 서비스 사업을 확대하고 있으며, 향후 이 사업 부문은 매년 100% 이상 성장할 것으로 기대하고 있습니다.
지적 재산권
꾸준한 연구개발 활동을 통해 축적된 다수의 지적 재산권과 많은 국내외 인증 및 수상 실적은 솔트룩스의 탁월한 기술력과 성과의 우수성을 대외적으로 인정받고 있음을 증명합니다.
AI as a Service, Welcome aboard! - 솔트룩스 이경일 대표이사 (AI SUMMIT 2020 SEOUL)
인공지능(AI, Artificial Intelligence) 기술은 아주 오랜 시간 동안 연구되고 발전해 왔습니다. 이미 1950년대부터 인공지능 기술 분야에 대한 연구가 시작되었는데, 초기에는 사람이 이해하고 사고하는 것처럼 기계에도 명시적으로 지식을 구축하고 논리(규칙)을 정의하는데 목표가 있었습니다. 기계가 더욱 복잡한 추론과 탐색을 가능하게 하는 것에 연구의 핵심이었고, 1980년대에 이르러서는 전문가시스템이라고 하는 형태로 더욱 연구되고 발전되었습니다.
2000년대에 들어서는 기계학습(Machine Learning) 분야의 연구가 시작되었는데, 시스템에 필요한 지식과 논리를 구축하는데 많은 시간과 노력이 소요되기 때문에, 기계가 스스로 학습하게 하여 그 한계를 극복하고자 하였습니다. 이후, 꾸준한 기계학습의 연구와 하드웨어의 발전이 동반되면서 2012년 이후 딥러닝(Deep Learning) 기술에 대한 연구가 급격히 성장하였고, 사람의 개입 없이 기계가 스스로 학습하여 다양한 분야에서 훌륭한 성과를 보이는 단계에 이르렀습니다. 이를 계기로 인공지능 분야에서의 접근 방식은 딥러닝 기술을 통한 발전으로 그 인식이 변화되어 왔습니다.
현재는 이러한 인공지능 기술의 발전이 실생활에 적용되어 서비스의 확대로 이어지고 있는데 이미 금융, 의료, 법률, 공공, 민간 등 다양한 산업 분야에서 인공지능 서비스가 구축되고 있습니다. 만족할 만한 서비스 수준을 위해서는 기계가 서비스 환경에서의 상호작용으로 더욱 더 지능화되어야 하고 다른 기술과 융합된 형태의 서비스가 요구된다는 점에서 단순히 기술적 성장뿐만 아니라, 서비스 관점에서의 발전이 필요한 단계입니다.
솔트룩스 AI Suite은 다음과 같은 10개의 엔진을 제공합니다.
시장 변화에 따른 제품 혁신의 통찰력
인공지능 분야의 발전 과정에서 보듯, 기술은 시장의 요구에 따라 빠르게 발전하고 있고, 이러한 기술발전에 따라 제품으로 완성되어야 비로소 실현 가능한 서비스로 활용될 수 있습니다.
솔트룩스는 창립 이후로 자연언어처리와 시맨틱, 추론을 포함한 인공지능 분야에서의 독보적인 원천기술을 연구해 왔습니다. 시맨틱기술과 지식그래프기술을 통해 명시적인 지식과 논리를 축적하여 시스템을 지능화하고, 빅데이터 기반의 기계학습과 딥러닝을 통해 통계적 패턴을 학습하여 시스템이 자가 성장할 수 있는 기술적 성과를 이루었습니다. 즉, 솔트룩스의 인공지능 기술은 지식 기반 추론과 데이터 기반 학습이 융합된, 상호작용을 통해 시스템을 지능화 하는 앙상블 인공지능(Ensemble AI)으로 제품화 되어 있습니다. 또한, 이러한 인공지능 기술이 실제 서비스에 활용될 수 있도록 언어, 음성, 시각 등 모든 데이터에 대해 인지, 이해, 지식, 추론, 예측의 각 과정에서 필요한 기능을 통합하고, 탁월한 성능을 보장하도록 완성도를 높이고 있습니다. 이처럼, 솔트룩스의 AI Suite 제품은 인공지능 기술의 융합을 통해 지능형 소프트웨어 솔루션과 서비스를 통합 제공하는 혁신적인 인공지능 플랫폼으로 발전해 가고 있습니다.
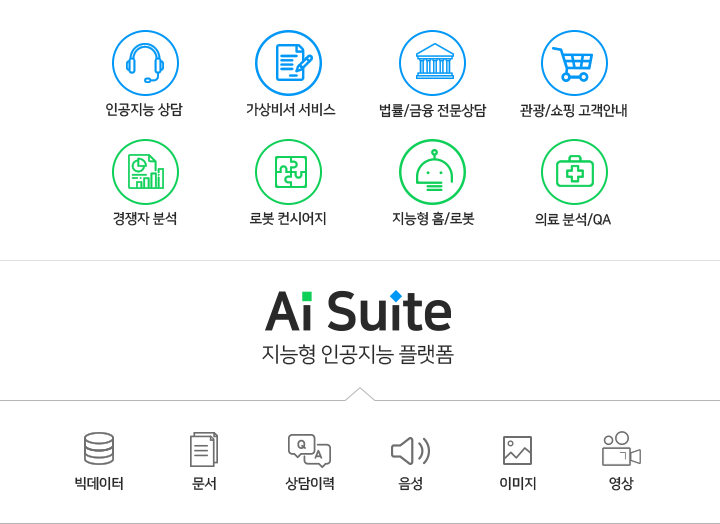
소개
AI Suite은 솔트룩스가 지난 20년간 투자해온 R&D의 결정체로써 언어지능, 음성지능, 학습/추론지능, 시각지능의 4개의 영역으로 구분하고, 각 분야별 원천기술을 개발한 결과물입니다. 국내 최초로 상용화된 인공지능 플랫폼 ADAM의 경우 아시아 최대 규모의 지식그래프를 내장하고 있으며 지식학습 및 추론을 통한 생활 질의응답의 경우 94% 수준의 정확도로 일반상식 수준의 질의에 대한 응답이 가능합니다. 각각의 엔진들은 적용 도메인에 따라 필요한 구성요소들을 조합하거나 ADAMS.ai를 통해 RESTful 형태로 제공되는 60여 개의 API를 결합 사용함으로 가상비서, 인공지능 상담원, 지능형 로봇 등 혁신적인 인공지능 서비스 구현이 가능합니다.
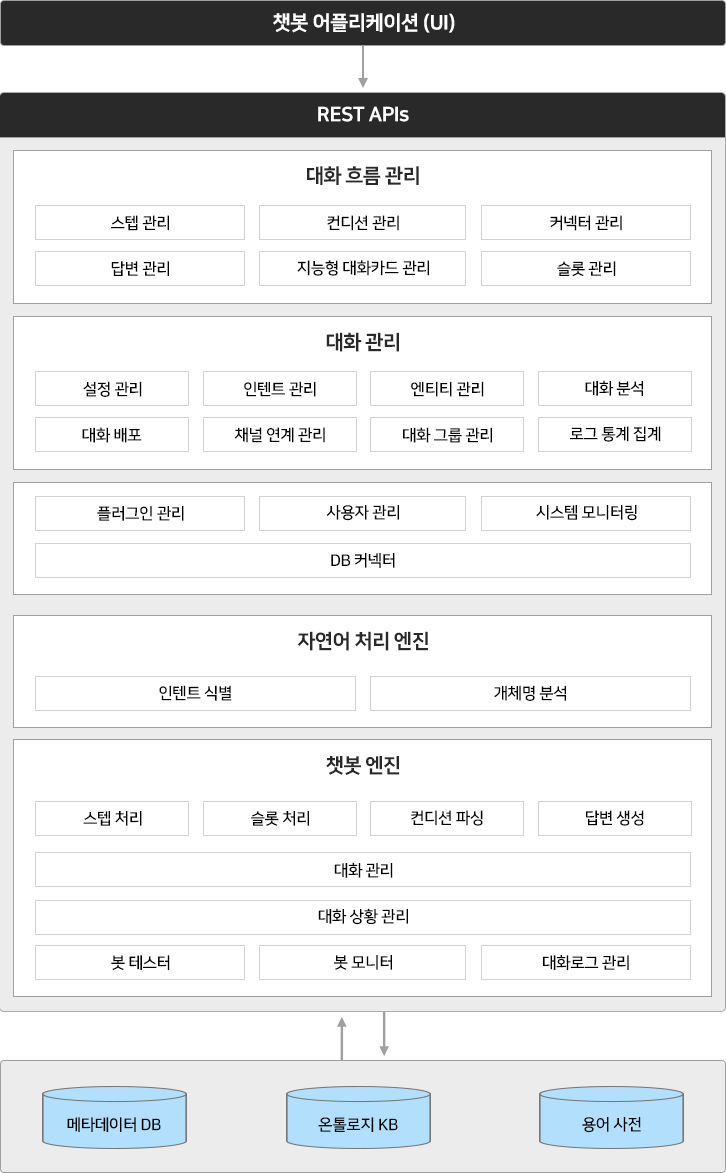
다음 그림과 같이 AI Suite은 다양한 인공지능 기반기술들을 활용하여 필요한 기능을 수행할 수 있도록 영역별 엔진들을 포함하고 있고, 하나의 지능형 지식처리 플랫폼으로 동작 할 수 있도록 구성되어 있습니다. 텍스트, 음성, 영상 등의 데이터에 대해 분석과 이해가 가능하고, 지식그래프 형태의 지식으로 구축되어 대화, 질의응답, 독해, 번역 등과 같은 지능형 지식처리에 활용됩니다. 또한 각각의 엔진은 적용하고자 하는 서비스 요구 기능에 따라 독립적, 선별적으로 적용이 가능하도록 설계되어 있어, 다양한 종류의 인공지능 서비스 구현에 효과적으로 활용할 수 있습니다.
< AI Suite 구성도 >
AI Suite은 인공지능 기반 실시간 가상 상담 및 상담 지원 서비스는 물론, 금융, 통신/방송, 법률/특허, 의료, 쇼핑/여행, 공공, 민간 등 지식 기반 고객응대가 즉각적으로 필요한 모든 분야에서 폭넓게 사용될 수 있습니다.
< AI Suite의 주요 활용 범위 >
주요 기능
AI Suite은 각 인공지능 분야별 주요 기술들에 대한 개별 엔진들을 아래 표와 같이 구분하고, 각 엔진별 최고 성능의 기능과 서비스를 제공합니다. 그 뿐만 아니라 적용 분야에 따라 커스터마이징을 통해 최적의 결과 제공이 가능하도록 사전 및 데이터구축, 모델 학습 등의 관리 기능을 함께 제공하고 있습니다.
주요 특성
주요 경쟁력
AI Suite은 자연어처리와 대화모델 위주의 기능만을 제공하는 일반적인 제품들과는 달리 다음과 같은 차별화되고 경쟁력 있는 기능 요소들을 지속적으로 연구 개발하여 제품화하고 있습니다.
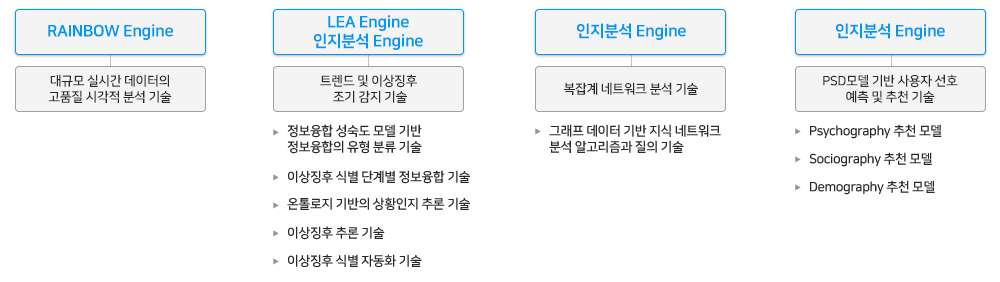
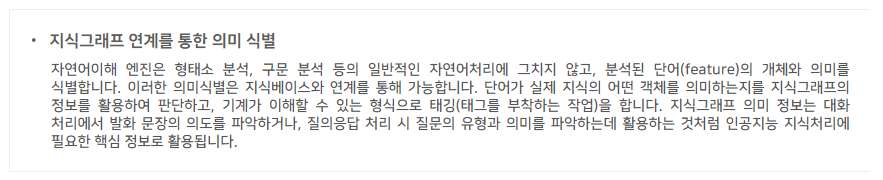
자연어이해 엔진LEA
자연어이해 엔진(LEA - Language Engineering & Analysis)은 비정형 데이터 가공을 위해 형태소 분석, 개체명 인식, 구문 분석, 감성 분석 등의 텍스트 분석 기능을 처리하는 기계학습/심층학습 기반의 언어 분석 엔진입니다. 그 뿐만 아니라 자연어처리 결과를 바탕으로 문장에 숨겨진 의도를 이해하거나 질문의 유형을 파악하는 등의 한 단계 높은 수준의 분석 결과를 제공함으로써, 대화처리를 위한 의도 이해 및 분석, 심층질의응답을 위한 질문 의미 이해 등이 가능합니다. 자연어이해 엔진(LEA)은 AI Suite에 포함된 다른 엔진들이 동작하기 위해 필요한 기본 엔진입니다.
자연어이해 엔진을 구성하고 있는 고정밀 언어분석기들은 기계학습과 심층학습(인공신경망) 기술이 적용되어 있으며, 대규모 언어자원(분야별 대용량 학습데이터, 사전과 규칙)을 통해 도메인별로 품질을 최적화할 수 있습니다. 형태소 분석기는 98% 이상의 분석 품질을 제공하고, 구문 분석과 개체명 추출기는 병렬/분산 처리를 통해 세계 최고 성능을 제공하고 있습니다. 한국어뿐 아니라 영어, 일어 등 다국어 대응이 가능하며, 지식그래프와 연계하여 의미해석, 질의응답, 대화 시스템 구현이 가능한 자연어처리 엔진입니다.
< 자연어이해엔진 - LEA 구성도 >
주요 특징
주요 기능 및 사양
주요 엔진 화면
음성인식 엔진STT
음성인식(Speech Recognition)이란 사람이 말하는 음성 언어를 컴퓨터가 해석해 그 내용을 문자데이터로 전환하는 처리를 말하며 STT(Speech-to-Text)라고도 합니다. 음성인식 엔진은 음성 인터페이스를 기반으로 하는 다양한 서비스에 활용하기 위해 음성인식 서비스를 제공하는 시스템입니다. 특히 AI Suite의 음성인식 엔진은 방대한 데이터를 사전 학습하였으며, 특정 도메인에 빠르게 적용하기 위한 전이학습 방식을 활용하여 적은 양의 데이터 학습만으로도 양질의 음성인식 서비스 제공이 가능합니다.
< 음성 대화 인터페이스 기반 서비스 구성 >
주요 특징
심층신경망 기반의 음성인식 학습AI Suite의 음성인식 엔진은 딥러닝(Deep Learning)에 의해 고도화된 음향모델 적응 학습을 기반으로 합니다. 일반적으로 사용되는 음성인식 알고리즘인 HMM(Hidden Markov Model) 또는, 기존 Fully connected DNN(Deep Neural Network) 기반 음향모델보다 개선된 음성인식 성능을 보이는 LSTM(Long Short-Term Memory)기술을 적용한 baseline 음향모델을 기반으로 적응 학습 환경을 제공합니다.
< 심층신경망 기반 음성인식 학습 개요 >
주요 기능 및 사양
음성인식 엔진은 RESTful 기반의 음성인식 서비스와 음향모델 및 언어모델의 학습 관리 기능으로 나눌 수 있습니다. 음성인식 서비스는 입력되는 음성데이터의 전처리, 특성 추출, 모델을 통한 텍스트 변환, 결과 보정 단계로 음성인식 결과를 제공합니다. 학습 관리는 음성-텍스트의 학습데이터로 음향모델과 언어모델에 대한 학습을 수행합니다.
< 음성 인식 엔진 구성도 >
주요 성능
아래 표는 적응학습 기반의 음성인식 품질 평가 결과입니다. Corr(Correct)는 음절단위맞춘 수, Acc(Accuracy)는 삽입, 삭제 오류를 고려한 정답률, H(hit)는 바르게 인식한 개수, D(deletion)은 묵음으로 인식한 수, S(substitution)는 다른 음절로 인식한 수, I(insertion)는 묵음이 다른 음절로 인식된 수를 의미합니다. 적응학습 이전의 베이스라인의 경우 음향 및 언어모델 모두 70% 이하의 정답률이었는데, 적응학습을 거친 후 두 모델 모두 97% 이상까지 향상되는 것을 확인할 수 있습니다. 개발된 음성인식 기술은 다양한 환경에서의 챗봇과 콜센터의 음성인식과 텍스트분석, 콜봇 시스템 구축 등에 활용되고 있습니다.
주요 엔진 화면
음성합성 엔진TTS
음성합성(speech synthesis)은 인위적으로 사람의 소리를 합성하여 만들어내는 것으로, 텍스트를 음성으로 변환한다는 데서 텍스트 음성변환(text-to-speech, TTS) 이라고 하기도 합니다.
AI Suite의 음성합성 엔진은 사람의 목소리를 학습하여 주어진 문장에 대하여 학습한 목소리와 유사한 어조와 억양으로 사람의 음성을 인공적으로 만들어 주는 엔진입니다. 특히, 이미 학습되어 있는 모델에 의한 목소리뿐만 아니라 특정 개인 목소리 또는 특정 도메인의 음성파일을 실시간으로 학습하여 사용자 각각의 특성이 반영된 목소리로 음성합성 모델을 생성할 수 있습니다. 음성합성 엔진은 이렇게 학습된 모델을 End-Point를 통해 개별 서비스로 제공함으로써, 다양한 인공지능 서비스에 활용할 수 있습니다.
주요 특징
주요 기능 및 사양
음성합성 엔진의 기능은 크게 학습 관리와 서비스 관리 영역으로 나눌 수 있습니다. 학습 관리 영역은 특정 음성데이터를 학습하여 새로운 음성합성 모델의 생성하거나 관리합니다. 서비스 관리 영역은 엔진을 통해 학습된 음성합성 모델을 서비스로 구성하여 타 서비스 애플리케이션에서 접근하고 사용할 수 있도록 배포 및 관리를 담당합니다.
< 음성 합성 엔진 시스템 구성 >
주요 성능
솔트룩스는 음성합성 개인화 서비스 실현을 위해 전이 학습 기술을 이용한 화자적응 방법을 사용하고 있습니다. 전이 학습이란 기존에 잘 훈련된 모델을 사용하여 유사한 문제를 가지는 새로운 모델을 학습하는 방법입니다. 전이학습은 새로운 모델의 학습 효율을 높여 적은 데이터양으로도 이미 학습된 모델의 가중치(Weight) 값들을 의미 있게 조정(Fine-tuning)하므로 높은 성능을 달성할 수 있습니다. 전이학습은 충분한 양의 데이터로 잘 학습된 A 모델에 기반하여 데이터가 부족한 B의 목소리를 효율적으로 학습하는 것이 가능합니다.
전이학습 시 사전 학습된 A 모델과 추가 학습할 B 모델의 분포가 큰 차이를 보이는 경우 음성합성 성능이 크게 떨어지게 됩니다. 솔트룩스는 이러한 데이터 부조화 따른 학습 성능 변이 문제를 해결하기 위해 여러 사람의 음성으로 이루어진 수십 시간의 데이터를 사용하여 음성합성 네트워크의 일부만을 미리 학습시켜 놓는 준지도학습(Semi-Supervised Learning) 방법을 추가로 적용하고 있습니다. 준지도학습은 전사 데이터 없이 음성 데이터만으로 학습을 수행하는 것으로, 인간이 글을 배우기 전에 말하는 법을 배우는 것과 같은 원리입니다. 솔트룩스는 전이학습과 함께 준지도학습 모델을 음성합성에 적용하므로 학습 시간을 현격하게 줄이면서 동시에 음성합성 성능을 극대화할 수 있습니다. 현재 솔트룩스의 음성합성 엔진은 30분 분량의 음성데이터로 특정인의 목소리를 학습, 높은 품질의 발화하는 것이 가능합니다.
주요 엔진 화면
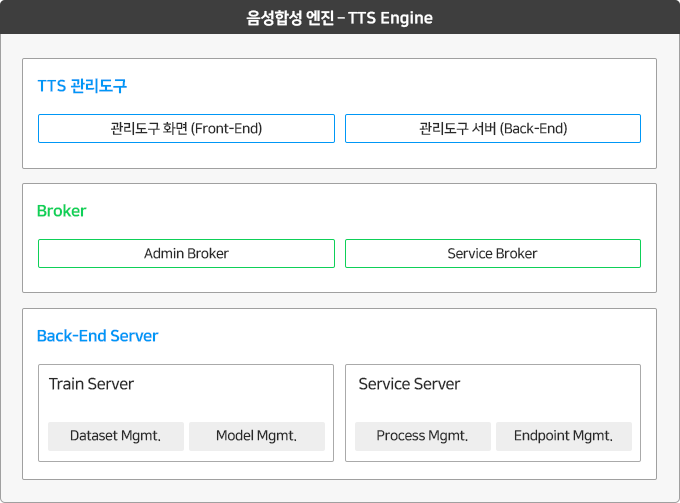
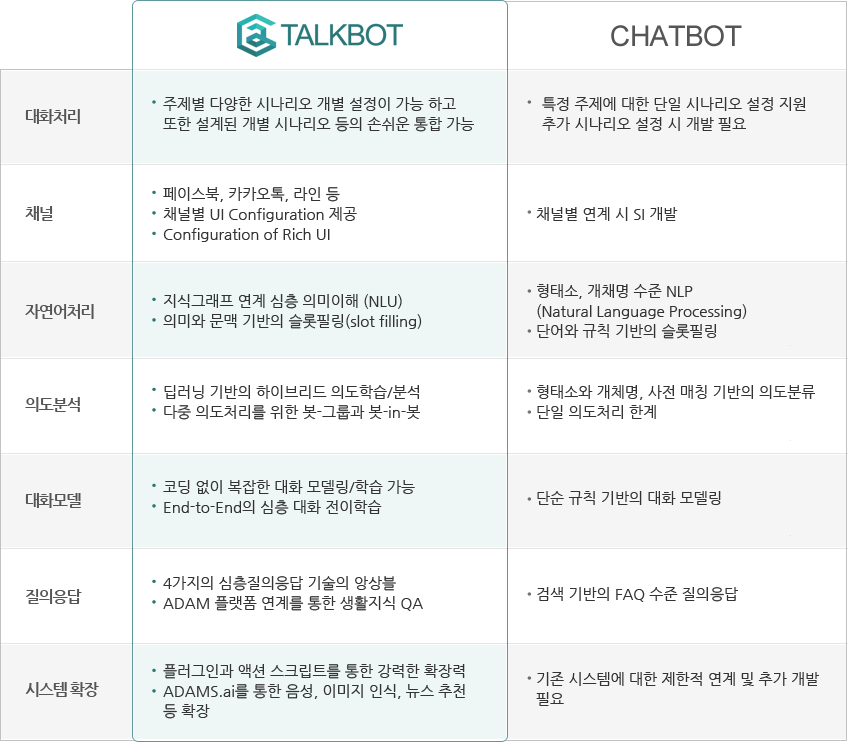
톡봇 대화 엔진Talkbot
AI Suite의 톡봇 대화 엔진은 솔트룩스에서 개발한 챗봇 플랫폼으로, 기존의 챗봇 시스템의 한계를 뛰어넘은 지식 기반의 심층 대화 시스템입니다. 기존의 챗봇이 간단한 자연언어처리와 규칙 및 문장 매칭 방식의 대화 매니저를 가지고 있다면, 톡봇 대화 엔진은 지식그래프와 복합추론 기반의 자연어이해 결과를 바탕으로 사용자 발화의 정확한 의미를 이해하고, 탁월한 답변을 제공하는 강력하고 유연한 대화모델을 생성할 수 있도록 지원합니다.
톡봇 대화 엔진을 통한 대화 서비스는 아래 그림과 같은 구조로 처리됩니다. 사용자는 다양한 채널을 통해 톡봇 대화 엔진에 메시지를 전달합니다. 입력된 메시지는 자연어이해 엔진을 통해 분석되고 대화 매니저는 학습된 대화모델을 통해 답변을 생성하여 음성, 텍스트, UX 등 적절한 방법으로 사용자에게 전달합니다. 톡봇 대화 엔진은 대화모델을 학습할 때 지식그래프, 선호추천, 사용자모델 등을 반영하여 모델을 학습한다는 점에서 기존의 대화처리 시스템들과 차이점이 있습니다. 또한, 대화모델로 처리하기 어려운 메시지에 대해서는 심층 질의응답을 통해 문제를 해결하며, 서비스 사용자와 대화 도중 문제가 발생하면 서비스 매니저를 통해 관리자가 대화에 개입할 수 있는 기능을 제공합니다.
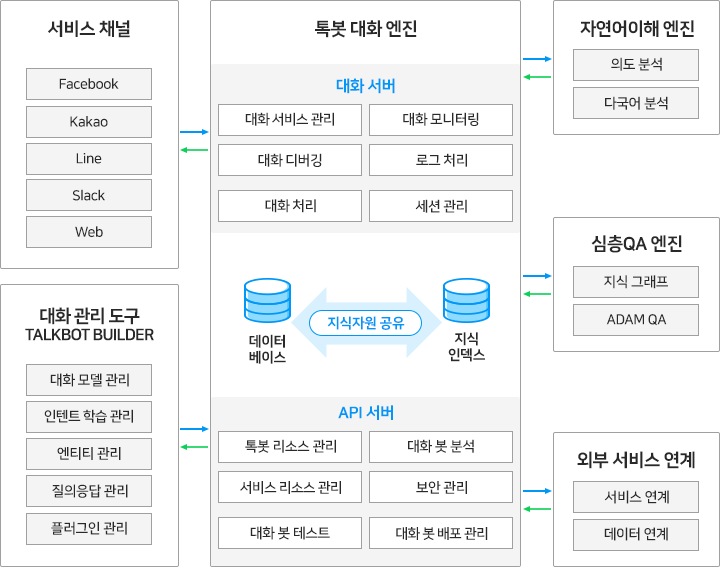
< 대화 처리 구조 >
주요 특징
주요 기능 및 사양
톡봇 대화 엔진은 크게 대화 서비스를 담당하는 대화 서버와 대화모델 학습 및 관리를 담당하는 API 서버로 구성됩니다. 다양한 서비스 채널을 통해 대화 서비스를 제공하고, 자연어이해 엔진, 심층질의응답 엔진과 연동하여 사용자 발화의 의도를 분석하거나 처리하지 못하는 질의에 대한 답변을 제공하기도 합니다. 또한, 플러그인을 통한 외부서비스 연계로 대화 처리 시 필요한 데이터나 기능을 활용할 수 있습니다. 이러한 톡봇 대화 엔진의 기능들은 대화 관리도구 인 톡봇 빌더를 통해 쉽게 운영 관리될 수 있습니다.
< 톡봇 대화 엔진 구성 >
강력한 ‘봇 빌더’ 내장
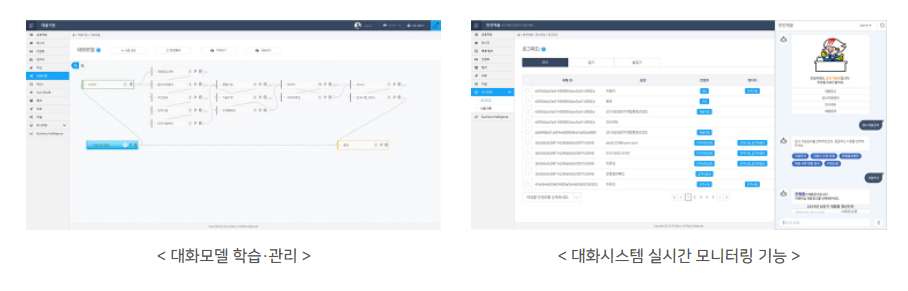
인공지능에게 언어와 대화, 지식을 가르치는 것은 늘 어려운 도전과제였습니다. 톡봇 대화 엔진은 코딩과 프로그래밍 기술 없이 마우스 클릭만으로 똑똑한 상담 봇을 만들고 다양한 채널로 즉각적인 서비스 시작이 가능합니다.
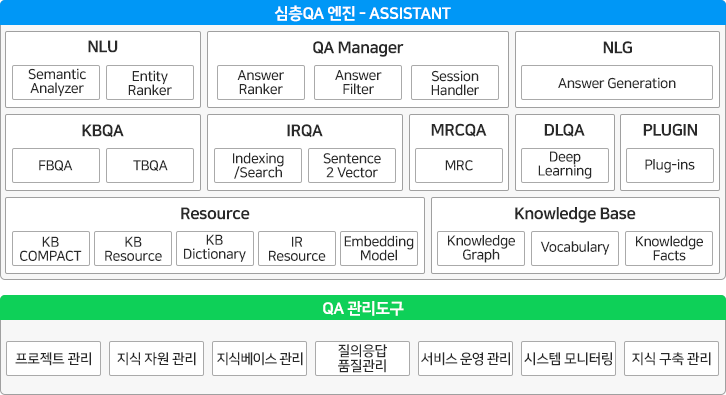
AI Suite의 심층QA 엔진은 사용자의 질문에 대해 다양한 지식을 스스로 학습, 추론하여 축적한 지식으로부터 최적의 답을 찾아내어 답을 제시하는 시스템입니다. 심층QA 엔진은 지식베이스 기반 질의응답기술(KBQA), 정보 검색 기반 질의응답기술(IRQA), 기계독해 기술을 이용한 질의응답기술(MRCQA), 상담 및 대화 이력 학습 기반 질의응답기술(DLQA) 등이 앙상블 되어 질의 유형에 따라 최적의 풀이 방식을 채택하여 사용자에게 응답을 제시합니다.
주요 특징
주요 기능 및 사양
심층QA 엔진은 자연어이해 엔진의 자연어이해 결과를 기반으로 정답을 찾기 위한 다양한 QA 방법을 적용합니다. 이 때, 지식그래프를 참조하여 자연어이해 및 답변 탐색 등을 수행합니다. 별도의 관리도구를 제공하여 도메인에 따라 심층질의응답을 위한 지식 구축, 관리, 서비스 모니터링 등을 수행할 수 있습니다.
< 심층QA 엔진 시스템 구조 >
앙상블 심층질의응답
심층QA 엔진은 고정밀 자연어이해 결과를 기반으로 지식베이스와 시맨틱 검색, 기계학습 및 딥러닝 등의 다양한 방법으로 답변을 탐색하는 앙상블 심층 QA를 제공합니다.① 지식베이스 기반 질의응답 (Knowledge Based Question Answering, KBQA)질문의 핵심 의미를 파악하고, 이를 지식그래프 저장소에 질의하여 답변을 탐색하는 방식입니다. 지식을 구조적으로 설계하고, 지식 구조에 맞게 지식베이스를 구축하기 때문에, 질문에 대한 정확한 답변을 질의할 수 있습니다. 또한, 지식 변경 및 유지 관리가 용이하고, 답변 품질을 지속적으로 높일 수 있습니다.
< 지식베이스 기반 질의응답 처리 개요 >
② 정보 검색 기반 질의응답 (Information Retrieval Question Answering, IRQA)
심층QA 엔진의 IRQA는 색인 기술 기반의 처리 방식과 심층인공신경망을 활용한 임베딩(Embedding) 기술 기반의 처리 방식으로 구분됩니다. 색인 기반의 IRQA는 가장 일반적인 질의응답 처리 방식으로 예상 질문-답변 데이터를 미리 구축해 두고, 사용자 질문과 유사한 질문 검색하여 해당 답변을 제공하는 방식입니다.
③ 기계독해 기반 질의응답 (Machine Reading Comprehension Question Answering, MRCQA)
사람이 직접 지식 구축을 하지 않아도, 기계가 문서를 읽고 질문에 대한 답변을 찾아 제시할 수 있도록 학습시키는 방식입니다. 대상 문서를 탐색하는 정보 검색 방식과 문서에서 답변을 찾는 기계독해(MRC) 방식을 결합하여 질문에 대한 답변을 제공합니다.
④ 대화 학습 기반 질의응답 (Dialog Learning based Question Answering, DLQA)
실제 상담이나 대화 이력, 질의응답 이력 등의 대화 데이터를 학습한 딥러닝 모델을 기반으로 질문에 대한 답변을 자동 생성하는 방식입니다. 학습을 위해 양질의 학습데이터를 대량으로 구축하고 지속적인 학습 및 평가를 통해 품질을 높일 수 있습니다. 딥러닝 모델이 생성한 답변을 직접 서비스 하거나, KBQA, IRQA 등의 질의처리와 병합하여 서비스 하는 앙상블 질의응답 처리로 활용할 수 있습니다.
< 대화 학습 기반 질의응답 처리 개요 >
주요 엔진 화면
기계번역 엔진
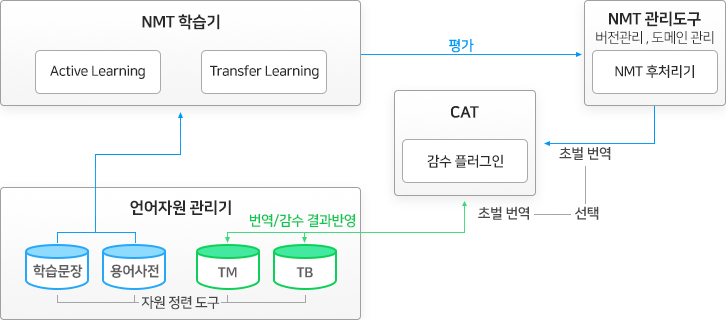
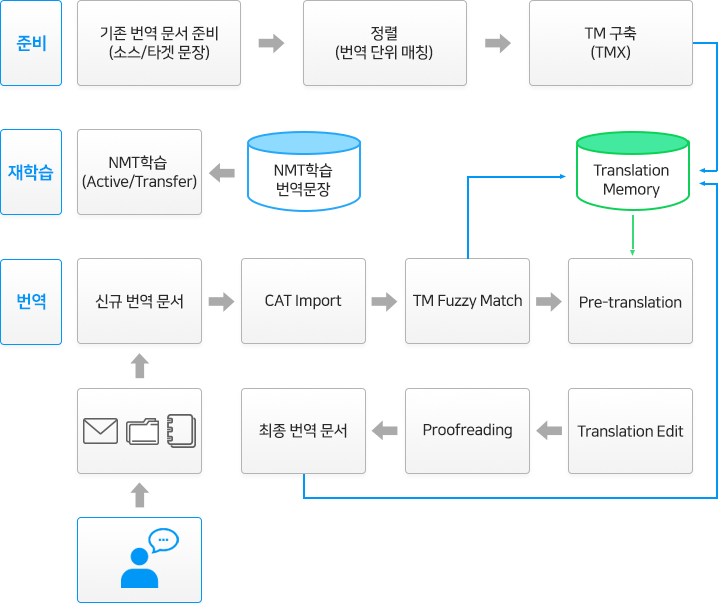
솔트룩스의 기존 통계기반 기계번역 엔진에서 더욱 발전된 인공신경망을 기반으로 한 기계번역 엔진입니다. 기계번역 학습을 도메인에 따라 특화할 수 있도록 CAT(Computer-assisted translation) 언어자원 관리도구를 통합 구성하여 지속적해서 번역의 품질과 생산성이 개선될 수 있도록 구성되어 있습니다.
< 인공신경망기계번역 엔진 개념도 >
주요 특징
자동번역 후처리 및 재학습을 통한 품질 향상
기계번역 엔진의 처리 구조는 NMT학습, 번역적용, 자산화, NMT 재학습의 선순환 구조로 이루어집니다. 이러한 시스템을 통해 번역 엔진을 사용할수록 자동 번역의 품질과 생산성이 더욱 향상되는 효과를 기대할 수 있습니다.
< 기계번역 엔진의 선순환 작업 구조 >
다양한 Office 도구와의 연동성
기계번역 엔진은 오피스도구와 연계를 가능하게 하는 Office플러그인을 제공합니다. 이를 통해 다양한 Office프로그램 내에서 기계번역의 결과를 즉시 활용할 수 있습니다.
주요 기능 및 사양
기계번역 엔진은 크게 번역자원과 각종 사전을 검색 관리하기 위한 데이터 영역, 기계번역이 수행 및 관리를 위한 NMT 영역, 그리고 시스템 사용자가 번역결과를 확인하고 관리할 수 있는 관리도구 영역으로 구성되어 있습니다.
< 기계번역 엔진 기능 구성도 >
주요 엔진 화면
기계독해 엔진MRC
기계독해 엔진은 질문에 대한 답을 찾기 위해 스스로 관련된 문서를 찾고 해당 문서로부터 답을 찾아 제시하는 엔진입니다. 특히 AI Suite의 기계독해 엔진은 솔트룩스가 보유한 다양한 지식자원을 활용하여 질문의 답을 찾는다는 점에서 기존의 기계독해 기술의 문서 입력에 대한 단점을 보완하였으며, 기계독해 서비스 사용자에게 문서 입력 없이 질문에 대한 답을 구하는 Open QA 형태의 서비스를 제시합니다. 또는 기계독해 엔진을 통해 문서에서 원하는 정보를 추출하는 용도로 활용할 수 있습니다.
주요 특징
Open QA로 활용
가능솔트룩스는 지난 20년간 수집해온 다양한 지식자원을 기계독해 엔진을 통한 QA에 활용합니다. 사용자로부터 문서를 입력받지 않아도 이미 보유하고 있는 지식자원에서 기계독해 엔진에 입력할 문서 또는 문단을 자동으로 추출함으로써, 사용자가 질문만 입력하여 답을 구할 수 있도록 질의응답 서비스로서의 활용성을 높였습니다.
< 문서 자동 검색/입력을 통한 기계독해 >
주요 기능 및 사양
기계독해 서비스
기계독해 엔진은 현재 별도의 관리도구를 제공하지 않으며 시스템 설치형으로 제공됩니다. 시스템 설치와 구동을 통해 기계독해 서비스에 접근할 수 있는 API가 동작하며 기계독해 엔진 사용자는 해당 API 활용을 통해 기계독해를 활용한 다양한 서비스를 구현할 수 있습니다.
< 기계독해 테스트 및 시각화 화면 >
주요 엔진 화면
복합추론 엔진
복합추론 엔진은 정형/비정형 문서로부터 추출된 지식들을 지식그래프 형태로 축적하고, 주어진 규칙이나 지식 간의 관계에 기반하여 새로운 사실을 탐색/추론함으로써 지식을 생성하는 엔진입니다. 특히, AI Suite의 복합추론 엔진이 제공하는 논리규칙 기반 연역추론과 기계학습 기반 귀납추론의 복합 적용으로 기 구축된 지식으로부터 새로운 관계를 도출하고 지식으로 활용하는 등 지식 증강 및 검증을 가능하게 합니다.
주요 특징
주요 기능 및 사양
복합추론 엔진은 대규모 시맨틱추론, 경험규칙기반추론, 시공간추론 등 다양한 추론기능을 통합 제공하고, 뿐만 아니라 신뢰 값 기반 확률/불확실 추론, 부재(default) 추론 등 관련 연구를 통해 지속적으로 기능을 확장하고 있습니다. 또한, 지식베이스 엔진과 연계하고 실시간 분산 처리 환경을 적용하여 초 대용량의 데이터로부터 초고속으로 추론된 결과를 제시합니다.
< 복합추론 엔진 구성도 >
주요 엔진 화면
지식학습 엔진KENT
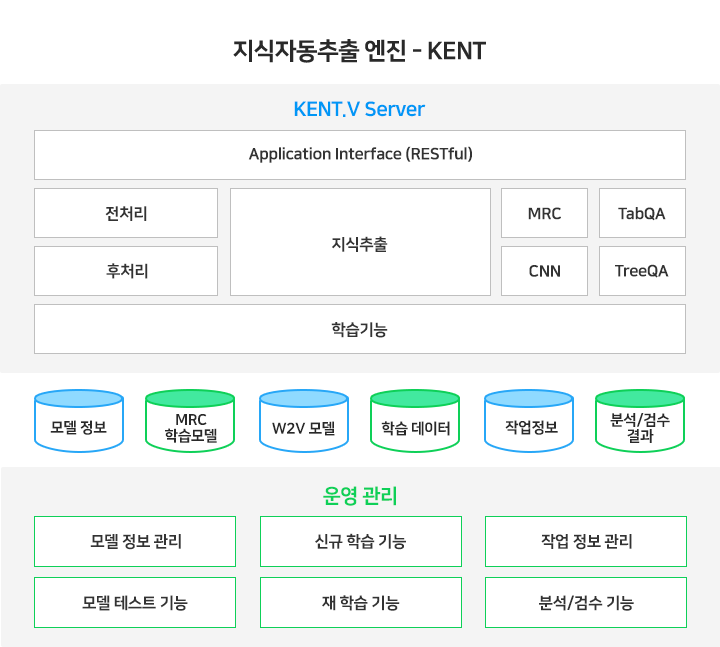
지식자동추출 엔진(Knowledge Extraction from Natural Language Text, KENT)이란 정형/비정형 데이터로부터 지식을 추출하고 지식 추출을 위한 모델을 학습 및 관리하는 엔진입니다. 추출된 지식은 지식그래프화 하여 질의응답, 대화처리 등 다양한 지식기반 인공지능 서비스에 활용될 수 있습니다. 지식자동추출 엔진의 기능만으로도 상품설명서, 계약서 등으로부터 유용한 지식정보를 추출하는 것이 가능합니다.
< 지식추출 및 지식그래프 생성 예 >
주요 특징
주요 기능 및 사양
지식학습 엔진은 지식학습 기능을 통한 지식 추출을 담당하는 KENT Server와 학습모델 관리, 작업 관리 등을 웹 상에서 운영할 수 있도록 하는 운영관리 Server로 구성되어 있습니다.
< 지식학습 엔진 시스템 구성 >
주요 엔진 화면
이미지인식 엔진
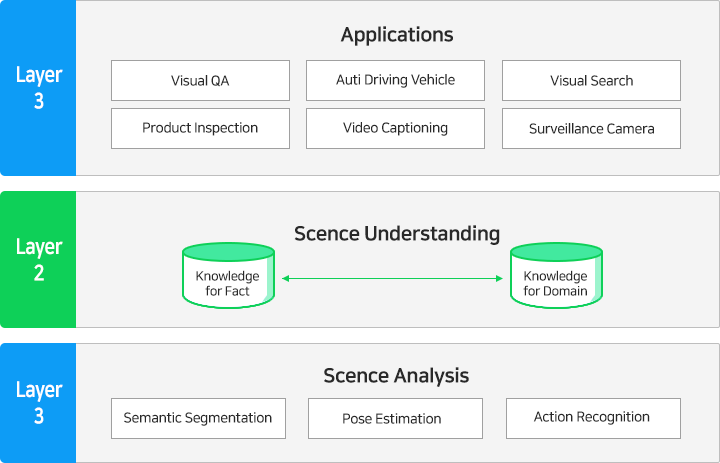
이미지인식 엔진은 이미지에 포함되어 있는 객체들을 인식하고 인식된 결과를 바탕으로 이미지가 어떤 장면인지를 분류할 수 있는 엔진입니다. 이미지인식 엔진은 향후 앞서 소개한 시각기반 검색, 비디오 캡셔닝, 자율주행, 시각적 질의응답 등의 응용 분야에 적용하기 위한 기반 기능을 지원합니다. 솔트룩스는 현재의 이미지인식 엔진의 고도화를 통해 이미지를 단순 설명하는 수준을 넘어 이미지속 장면의 의미를 이해하는 수준으로 발전시켜 아래 그림과 같은 기술 스택을 달성할 계획입니다.
< 이미지인식 엔진 기술 스택 >
주요 특징
주요 기능 및 사양
이미지인식 엔진은 카메라 등을 통해 들어온 이미지를 실시간으로 처리해 상황을 인식하고, 인식된 정보를 응용 어플리케이션에 제공하는 역할을 합니다. 이를 위해 이미지에서 다양한 정보를 분석하는 시각 분석 모듈과 분석된 정보를 바탕으로 상황을 이해하기 위한 시각 이해 모듈로 구성될 수 있습니다.
< 이미지인식 엔진 구성도 >
주요 성능
앞서 소개한 이미지 인식 엔진의 각 기능들은 지속적인 연구 및 개발 진행 중에 있습니다. 현재까지의 SOTA(Status-Of-The-Art)는 아래 표와 같습니다.
적용사례
인공지능 상담 시스템 구축 사례
상담사 및 대고객 질의응답 서비스 - NH농협은행
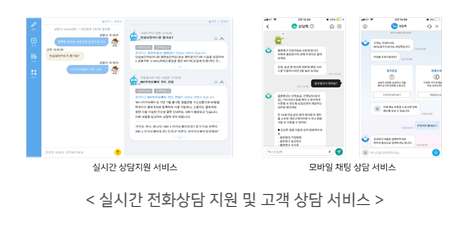
최근 금융 분야에서는 모바일을 비롯한 다양한 고객 서비스 채널이 확대되고 있고, 최신 인공지능 기반의 기술 트렌드에 대응하는 서비스 요구가 증가하고 있습니다. NH농협은행에서도 여러 디지털 채널을 통한 인공지능 상담 서비스의 필요성이 대두되고 있습니다. NH농협은행 고객행복센터는 상담사와 고객, 온라인과 오프라인 등 인공지능 상담 서비스가 필요한 모든 환경을 수용하여 서비스 채널을 확대해 나갈 수 있도록 시스템 인프라를 구축하는 것을 목표로 합니다. 이를 통해 고객행복센터가 인공지능 서비스의 중추적 역할을 담당하고, 전체 금융 분야를 선도할 것으로 기대하고 있습니다.
① 사업의 내용
(고객상담 질의응답 서비스 구축) 고객 상담 지식에 대한 질의응답 서비스 제공. 모바일앱을 통한 채팅상담 서비스를 통해 사용자 질문을 입력 받아 해당하는 답변을 찾아 텍스트로 제공하거나 계좌 조회나 이체 등의 서비스로 연결
(실시간 전화상담 지원 서비스 구축) 상담사와 고객의 전화상담 내용을 실시간으로 텍스트로 변환하여, 질문에 대한 답변을 제공. 상담사가 직접 질의하는 것과는 달리, 상담 중에 인공지능 시스템에 의해 제시되는 내용을 참고로 하여 빠른 고객대응이 가능
(인공지능 가상 상담 서비스 ‘콜봇’ 구축) 고객의 상담 전화를 인공지능 시스템이 먼저 수신하여 간단한 질문에 대한 답변을 하거나 전문 상담사로 연결. 대화 모델을 통해 대화형 상담을 제공하고, 일반 질문은 질의응답 시스템으로 답변을 제공
(안내 로봇 상담 서비스) 안내 로봇으로 농협은행 인공지능 시스템에서 제공하는 API를 연계하여 고객 상담 및 안내 서비스 제공. 상담 내용에 대한 대화모델 구축과 질의응답 시스템 연계를 통한 고객 상담 제공
< 가상상담 콜봇 서비스 및 로봇 상담 서비스 >
② 적용 기술 및 솔루션
AI Suite 제품 적용 상담 서비스 제공 시, 서비스 시나리오에 따른 대화 흐름 처리와 질의응답 제공을 위해 AI Suite의 자연어이해 엔진, 심층QA 엔진, 대화처리 엔진, 기계독해 엔진 적용
③ 주요 성과
인공지능 상담 시스템을 활용하여 직원과 고객을 대상으로 모든 채널에서 서비스를 확장할 수 있는 시스템 인프라 구축
심층QA 엔진과 대화처리 엔진의 연계를 통해 대화형 상담 서비스 제공. 대화를 통해 고객의 질문 의도를 파악하여 답변함으로써, 질문 의도가 불분명한 단순질의에 대한 답변역량을 향상할 수 있고, 추가 질문으로 연속적인 상담을 이어 나갈 수 있어 의도하는 서비스를 원활하게 제공 가능
콜센터 상담원의 업무 보조 역할을 하는 상담도우미 운영을 통한 상담 품질 향상 및 상담원 업무 전문성 강화
농협은행 모바일앱인 올원뱅크 및 스마트뱅킹 앱 내에 상담톡 서비스를 탑재하여 일반 사용자들에게 서비스를 확대
국내 최초 인공지능 전화 상담 서비스 콜봇(Call Bot) 개발 및 상용화. 기존 ARS 안내에 대비하여 보다 빠른 대응이 가능하고, 상담사도 전문 상담에 집중 가능. 안내로봇 Pilot 시스템 구축으로 영업점과 같은 오프라인 채널에서 안내로봇 운영을 통한 대화형 상담 및 지식 서비스 제공 가능성 확인
지능형 지식관리 시스템 구축 사례
지능형 지식관리 시스템 - NH농협은행
고객콜센터 및 전 영업점에서 고객상담에 필요한 업무 지식을 관리하고 공유하는 지식관리 시스템을 인공지능 시스템에서 활용 가능한 형태로 개선하였습니다. 지식 생성, 관리, 검색 등의 사용 편의성을 높이고, 지식 콘텐츠 생성 시, 업무 분야와 속성에 따라 구체적으로 관리되도록 하여 Knowledge-Graph 기반의 지식베이스로 변환 저장합니다. 이는 자연어 콘텐츠를 시스템이 이해 가능한 형태(machine readable)의 지식 데이터로 자동 변환을 시도하는 것이며, 이 과정은 인공지능 기반 지식자동추출을 통해 지식 데이터를 추출하고 시맨틱 복합추론을 통해 지식베이스로 변환 및 저장되도록 적용하였습니다.
< 지능형 지식관리 시스템 개요 >
① 사업의 내용
(지식 콘텐츠 생성 관리) 지식 추출 및 지식그래프 형태의 변환을 고려하여 계층 구조로 업무 카테고리를 정의하고, 각 카테고리 별 단위 지식 콘텐츠 생성 관리할 수 있도록 세분화된 콘텐츠 관리도구 구축
(지식 데이터 자동 추출) 비정형 텍스트로 작성된 지식 콘텐츠를 분석하여 지식 데이터 후보를 자동으로 추출. 콘텐츠 내용에서 자연어이해 처리를 통해 대상 지식을 식별하고, 딥러닝 기반 학습 모델을 통해 데이터를 추출하는 지식자동추출 과정이 적용. 추출된 지식 데이터는 지식그래프 기반으로 저장할 수 있도록 트리플(triple) 형태로 변환
(지식학습 검증 및 관리) 자동 추출된 지식 데이터를 검증하고 편집할 수 있는 품질 관리 환경 구축. 지식자동추출의 품질과 성능을 지속적으로 개선
② 적용 기술 및 솔루션
AI Suite 제품 적용 지식 콘텐츠로부터 지식 추출 및 저장 관리를 위해 AI Suite의 자연어이해 엔진, 지식학습 엔진, 복합추론 엔진 적용
③ 주요 성과
지식자동추출 및 지식 추출은 아직까지 많은 연구 개발의 노력이 필요한 기술 분야입니다. 품질 향상을 위해 언어처리와 기계학습을 포함한 다양한 방안들을 연구하였고, 해당 도메인의 콘텐츠로부터 필요한 지식을 추출하는 범위에서는 만족할 만한 수준의 성과를 보였습니다. 지식자동추출을 실제 서비스에 적용한 성공 사례로 볼 수 있습니다.
지식관리 시스템에서 관리되는 지식 콘텐츠가 인공지능 시스템에서 활용될 수 있어 지식 활용성이 높아지고, 각각 관리되던 지식정보를 일원화하여 지식 유지 관리에 대한 비용이 절감하고 편의성이 증대되었습니다.
챗봇 서비스 구축 사례
내부 업무 지원을 위한 챗봇 서비스 도입 사업 – 한전 KDN
본 사업은 한전 KDN의 챗봇 서비스 도입 사업으로 고성능의 자연어처리, 인텐트/엔티티 맵핑 기술, 대화모델링 등 기본적인 대화처리 엔진의 적용과 향후 다양한 지식에 대한 효과적인 질의-답변 제공이 가능한 시스템으로 확장하기 위한 지식그래프 연계 등의 업무를 수행했습니다. 한전 내부 직원들의 편의를 위해 접근성이 용이한 메신저 플랫폼 기반으로 실지 업무에서 직면하는 출장업무와 ICT 장비대여, 업무담당자 연계 등의 분야에 관한 단순지식 제공을 넘어 맞춤형 답변 서비스를 제공하는 것을 목표로 합니다.
< 한전 KDN 챗봇 서비스 구성도 >
① 사업의 내용
(도메인 사전 구축) 내부 직원들로부터 자주 문의되는 질의 수집 및 용어사전 구축
(업무 프로세스 대화모델 구성) 각 업무 프로세스에 따라 챗봇이 동작할 수 있도록 대화모델 구성
(문장 분석) 컨설팅을 통해 도출된 다양한 인텐트를 적용하고, 인텐트 추출 적중률을 높이기 위해 상담내용 문장 분리하여 인텐트 분석에 활용
(안내 서비스 구현) 출장여비제도 안내 및 ICT 장비대여 업무 안내 서비스 구축
② 적용 기술 및 솔루션
AI Suite의 대화처리 엔진 및 심층QA 기술 선별적 적용
③ 주요 성과
지식 기반 업무지원으로, 단순 지원업무를 위한 인적자원 소비 감소로 주요 업무에 대한 업무효율성 향상
복잡한 논리흐름도(Logical flow chart)를 자체 생성하여 다양한 작업 상황에 대해 구체적 조치 가능
업무 절차에 대한 질의응답 뿐만 아니라 그룹웨어 연동을 통한 업무 신청, 예약 등을 하나의 메신저 플랫폼 상에서 가능
추천 서비스 구축 사례
방송 콘텐츠 추천 시스템 구축 – KBS (한국방송공사)
개방형 기술 환경과 방송/통신 융합과 같은 서비스 환경, 그리고 진화된 콘텐츠 소비 구조로 인해, 필요한 콘텐츠를 손쉽게 발견하고 소비할 수 있는 환경의 필요성이 점점 부각됨에 따라, 사용자의 특성과 상황에 따른 맞춤형 콘텐츠 추천 기술을 개발하게 되었습니다. 본 사례에서는 언어분석, 검색, 마이닝, 시맨틱기술 등 다양한 기술들을 이용하여 방송 영상 콘텐츠 및 관련 콘텐츠들에 대한 사용자 맞춤형 방송 콘텐츠 추천 검색을 연구 개발하였습니다. 방송 콘텐츠 추천 검색 시스템은 크게 데이터 수집, 콘텐츠 검색, 콘텐츠 추천, API 서버, 4개의 시스템으로 구성되고, 이를 각각의 독립된 시스템으로 나눌 수 있으며, 독립된 시스템은 데이터 수집, 콘텐츠 색인, 콘텐츠 분석, 콘텐츠 탐색, 콘텐츠 검색, 사용자 분석, 콘텐츠 추천으로 구분되어집니다.
< 방송 콘텐츠 추천 시스템 구성도 >
① 사업의 내용
(콘텐츠 및 선호데이터 플랫폼) 콘텐츠 분석을 위한 KBS 내의 방송 메타 데이터와 관련 정보, 사용자 분석을 위한 사용자 프로파일 정보와 방송 서비스 이력 및 사용자 피드백 정보 등에 대한 수집 및 저장 관리.
(추천 검색 플랫폼) 사용자의 콘텐츠 소비 이력 데이터를 분석하여 콘텐츠를 소비한 사용자의 패턴이 다른 콘텐츠의 소비 사용자들과 얼마나 비슷한 지 유사 정도를 도출하고 이를 기반으로 콘텐츠 추천 검색 결과를 제공.
(추천 검색 알고리즘 개발) 수집된 콘텐츠 메타데이터의 특성을 기반으로 콘텐츠 간의 유사성 또는 연관성을 분석하여 사용자의 입력(검색어, 메뉴, 콘텐츠)에 따라 콘텐츠를 추천하는 콘텐츠 기반 알고리즘과, 사용자 개인의 선호 정보, 프로파일(Profile)을 기반으로 사용자 기반 협업 필터링 기법과 아이템 기반 협업 필터링 기법을 활용한 사용자 기반 추천 알고리즘 구현.
(추천 검색 관리) 수집 관리, 색인 관리, 기획 관리, API 관리, 콘텐츠 관리 등 추천 시스템에 필요한 데이터 및 서비스 관리 기능 구현.
(추천 검색 활용 서비스) 추천 검색 인터페이스 개발 및 이를 활용한 프로그램 관련 메뉴 및 관련 추천 페이지, 콘텐츠/키워드/인물 기반 추천 검색, 맞춤 추천 작품, 최근 추천 작품 등 활용 서비스 구현.
② 적용 기술 및 솔루션
AI Suite의 자연어이해 엔진 및 복합추론 엔진
③ 주요 성과
방송 콘텐츠 추천 서비스를 위해 추천 검색 연구 동향을 파악하고 기존 추천 시스템 사례를 바탕으로 추천 시스템의 구성요소와 추천 알고리즘, 목표 기능과 서비스를 기획, 연구 개발.
방송 메타데이터 표준에 따른 모델링을 기반으로 방송 콘텐츠 데이터 및 메타데이터, 사용자 이력 정보를 수집. 사용자 이력정보는 각 추천 알고리즘에 따른 추천 모델을, 방송 콘텐츠 데이터와 메타데이터는 텍스트 마이닝과 통계 기법으로 추천 모델을 구현.
콘텐츠 추천 검색을 적용하여 OHTV 추천 서비스 정합에 사용하고, 추천검색 웹 페이지에 적용하여 추천검색 시스템의 활용 서비스를 구축.
추천검색 엔진 활용 방안의 연구로 KBS 통합 CMS에 적용하여 소비 이력 기반 추천, 선호 인물 추천, 선호 장르 추천, 그룹/성별/연령 추천, 복합 추천으로 총 5가지 추천 기능을 제공하는 사용자기반 추천검색 서비스를 개발.
인공지능 스마트 뉴스 추천 앱 서비스 구축 – 지니뉴스 (Ziny News)
뉴스와 소셜 콘텐츠는 인공지능을 통해 분석할 수 있는 빅데이터의 핵심입니다. 솔트룩스는 1,200여개 이상의 국내 온/오프라인 뉴스 및 소셜 미디어를 인공지능 엔진이 실시간으로 분석하여 30만명에 달하는 개인 사용자에게 맞춤형 정보를 추천하고 제공하는 스마트 뉴스 앱 ‘지니뉴스’ 서비스를 구축하였습니다.
지니뉴스 인공지능 엔진은 하루 700만건의 뉴스와 블로그를 사람처럼 읽어내고, 500여 카테고리로 자동 분류할 뿐 아니라 떠오르는 이슈들을 자동 인지해 맞춤 서비스를 제공합니다. 특히, 맞춤 뉴스 기능은 등록된 관심 키워드 뉴스 뿐만 아니라 딥러닝 기술을 사용해 각 사용자가 읽은 콘텐츠의 내용을 학습하고, 학습된 결과에 기반을 둬 사용자가 좋아할 만한 콘텐츠를 자동 예측, 추천해줍니다. 일종의 각 사용자 별 인공지능 페르소나와 각 개인별 맞춤형 인공신경망을 생성해 콘텐츠 추천을 진행하는 것으로, 사용자의 개인 정보를 수집하지 않고 인공지능 엔진이 익명화 된 인공신경망을 통해 개인 맞춤형 뉴스 추천 서비스를 진행한다는 점이 특징입니다.
① 사업의 내용
딥러닝 기반 사용자 맞춤 콘텐츠 추천 딥러닝 기반의 사이코그래피(Psychography) 학습과 데모그래피(Demography) 기반 융합 추천 기술 연구 및 이를 활용한 뉴스 추천 서비스 개발
심층 뉴스와 소셜 콘텐츠의 지능적 큐레이션 대규모 콘텐츠 실시간 분석을 통한 핵심 콘텐츠 및 주요 이슈(주제) 도출. 카테고리 별 콘텐츠 분류 및 시맨틱기술 기반 연관/유사 콘텐츠 분석 제공.
보다 진화된 사용자 경험(UX) 제공 사용자 편의성과 콘텐츠의 가독성을 높이는 UI/UX 구현. 관심 콘텐츠의 개인화 및 소셜 공유 기능 구현.
② 적용 기술 및 솔루션
AI Suite의 자연어이해 엔진 및 복합추론 엔진
③ 주요 성과
(커버스토리) 놓치지 말아야 할 오늘의 이슈들을 실시간으로 제공. 중복 뉴스 제거, 랭킹 뉴스, 속보, 3분 브리핑 등 다양한 스타일의 카드 뉴스 제공으로 오늘의 핫이슈 확인.
(뉴스/소셜 스트림) 국내 언론사 뉴스와 소셜미디어 콘텐츠 실시간 수집하여 주요 뉴스, 재미 있는 볼거리 등 다양한 콘텐츠 제공. 사용자가 관심 있는 분야별/주제별 카테고리만 선택하여 뉴스와 소셜미디어 콘텐츠 제공.
(맞춤 뉴스) 등록된 관심 키워드를 기반으로 뉴스, 소셜미디어 구분 없이 해당 주제의 보고 싶은 콘텐츠를 선별하여 제공.
(3분 브리핑) 매일 정치, 경제, 세계, IT, 스포츠 등 중요한 뉴스만을 골라 요약된 정보로 브리핑 제공.
(지니 추천) 사용자 개개인을 연구하고, 분석하여 개인이 선호할 만한 재미 있는 콘텐츠를 선별하여 제공. 자체 추천 알고리즘을 통해 주제별, 연령별, 성별 등 다양한 콘텐츠를 제공.
(아티클 뷰어) 사용자의 편의성과 가독성을 고려하여 광고 없는 스마트뷰를 제공.
(뉴스 연대기 / 연관 뉴스) 기사가 담고 있는 토픽일 분석하여 시간순으로 자동 구성되며 기사의 흐름을 한눈에 확인할 수 있도록 제공. 그 외 연관된 토픽 기사들을 추천하여 다양한 볼거리 제공.
해외 사례
[일본] 인공지능 상담 시스템
솔트룩스는 일본 금융과 항공 산업에 인공지능 상담 시스템, 가상 상담 비서 서비스를 도입했고 기계학습, 지식추론 및 심층 질의응답과 같은 인공지능 기술을 상용화했습니다. 인공지능 상담 시스템 도입을 통해 고객 이탈방지, 시스템 스스로 해결, 고객만족도 향상 등의 효과를 보았고 기업 이미지 및 영업이익 증가와 실질적인 고객 만족도 상승에 기여했습니다.
< 일본 인공지능 상담 시스템 도입 사례 >
① 사업의 내용
(미즈호 은행 가상상담) 사람이 질문하는 말의 의도를 이해하고 적절한 내용과 답변을 찾아 실제 상담원(사람)처럼 대답을 제공하는 컨시어지(Concierge) 개념의 서비스 구축. 미즈호 은행 고객의 문제 해결을 위해 비즈니스 웹사이트에서 Push Type의 네비게이터 미나(Mi-na) 서비스를 제공.
(마넥스 증권) 마넥스(Monex) 증권 홈페이지에서의 상담 서비스 구축.
(손해보험재팬 주식회사) 손해보험재팬日本興亜주식회사 공식 홈페이지에서 고객의 궁금사항 해결을 도와주는 ‘날마다 지킴이(日々乃まもり)’ 서비스 구축.
(전일본공수 주식회사) 전일본공수 주식회사(ANA, All Nippon Airways)의 ANA SKY WEB에 아미(Amy) 서비스 구축
< AI Suite 해외 적용 사례 >
② 적용 기술 및 솔루션
AI Suite 제품 적용 상담 서비스 제공을 위해 AI Suite의 자연어이해 엔진, 심층QA 엔진 적용
③ 주요 성과
고객 이탈 방지 문의 진행중 고객에게 필요한 정보를 적절히 제공함으로써 고객이 서비스 페이지에서 문제 해결 도중 이탈을 방지함
상담 횟수 감소 고객 상담센터 문의 내용을 컨시어지 서비스가 대신함으로써 상담 전화 횟수 및 문의 메일 건수의 감소
고객만족도 향상 서비스 모니터링을 통해 부족한 지식을 보완하여 품질 향상. 서비스 사용자의 평가율이 지속적으로 증가하여 실제 고객 만족도 상승 확인
기술소개
AI Suite은 4차 산업혁명 시대에서 요구되는 문자, 음성, 시각, 학습, 대화 등의 인공지능 기반기술들의 집합체입니다. 솔트룩스는 각 분야의 원천기술을 자체화하고 이들을 다양한 산업 분야에 적용함으로써 그 성능과 효율성을 검증해왔습니다. 지금까지 확보한 기술과 제품들을 기반으로 향 후 우리 생활에 필수 요소로 자리잡을 자율주행, 인공지능 가상비서 등의 기술 시장을 선도해 나가도록 할 것입니다. 아래 표는 AI Suite를 이루고 있는 엔진들과 해당 엔진을 구현한 주요 기술들을 나열한 것입니다.